本文描述redis的Sorted Set底层实现所用到的数据结构,包括skiplist、dict、ziplist
Sorted Set 要解决的问题
Sorted Set 是一个有序集合,用于解决去重、按分值排序、查询和范围查询的问题
skiplist
skiplist 的基本思想:二分查找
第一层:对于有序链表,查询时间复杂度是O(n)

第二层:对第一层每相邻两个节点增加一个指针,让指针指向下下个节点,需要比较的节点数大概只有原来的一半

第三层:对第二层每相邻两个节点增加一个指针

整个查找过程类似于二分查找,时间复杂度降低至O(logn)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系,而还需重新维护这种关系
skiplist 的结构
1 |
|
skiplist 的构造过程
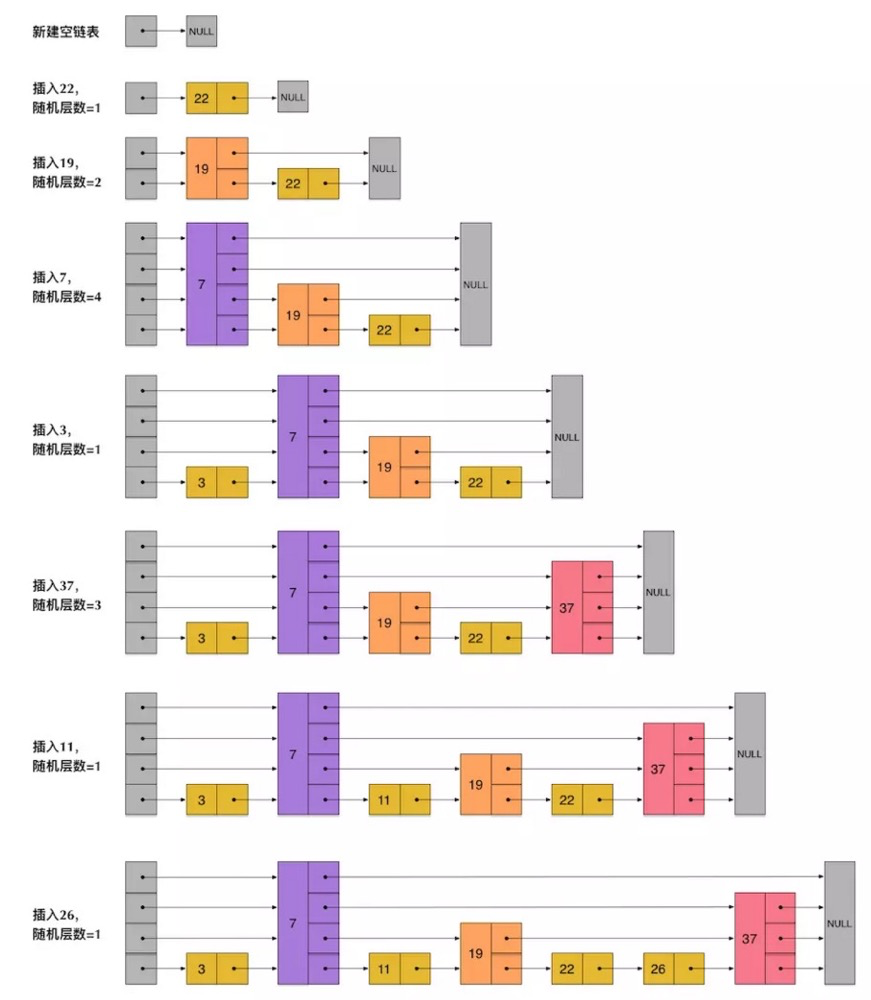
为了避免上面提到的问题,skiplist在构建中不要求两层链表之间严格的对应关系,而是为每个节点随机设置一个层数,每个节点的随机层数的计算过程如下:
- 每个节点都有第一层指针
- 如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p
- 节点最大的层数不允许超过一个最大值,记为MaxLevel。
构造过程如下图
搜索过程
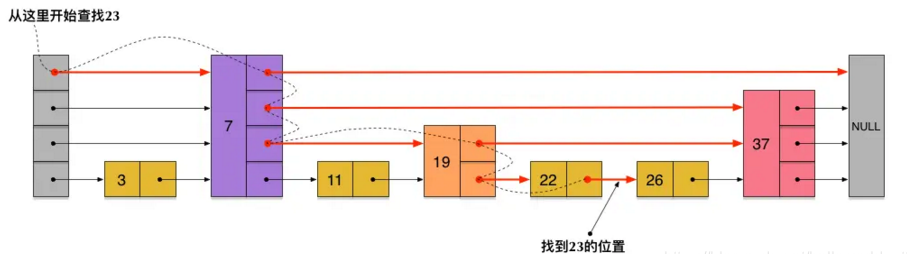
应该从哪层开始搜索呢?
在一个16节点的skiplist中,p=1/2,可能存在一种情况是:第一层有9个节点,第2层有4个节点,第三层有2个节点,第14层有1个节点。如果直接从14层开始搜索,将会做很多无用的工作
根据节点层数随机算法,可以得到:
第一层固定有n个节点
第二层期望有n*p个节点
第三层期望有n*p2个节点
...
假设我们将从第L层开始搜索,期望有1/p个节点。令n*pL-1=1/p时,得到当L=log1/pn时,会发生这种情况。故我们从第L=log1/pn层开始搜索
复杂度分析
时间复杂度
设C(k)表示在无限列表中爬k个层级后,所需要走过的平均查找路径长度,则 \[ \begin{align*} & C(0)=0\\ & C(k)=(1-p)*(C(k)+1) + p*(C(k-1)+1)\\ & C(k)=\frac1p+C(k-1)\\ & C(k)=\frac{k}{p} \end{align*} \] 这个结果的意思是,我们每爬升1个层级,需要在查找路径上走1/p步。而我们总共需要攀爬的层级数等于整个skiplist的总层数-1
由于我们是从L层开始搜索,故总路径长度 = (L-1)/p
将L=log1/pn代入,得到总路径长度 = (log1/pn-1)/p
当p=1/2时,2*log2n-2,即O(logn)
空间复杂度
\[ 1*(1-p)+2*p(1-p)+3*p^2(1-p)+...=(1-p)\sum_{k=1}^{+∞}kp^{k-1}=(1-p)*\frac{1}{(1-p)^2}=\frac{1}{1-p} \]
当p=1/2时,每个节点平均包含的指针数为2;则总的空间复杂度为O(n)
skiplist与平衡数的比较
- 内存占用:平衡数的内存占用情况是不可调整的,skiplist可通过参数控制
- 范围查找:zset有很多范围查询,在平衡树中需要先找到较小的值然后通过中旬遍历找到较大的值,中旬遍历操作较复杂
- 实现成本:平衡树维护平衡关系的操作较复杂,skiplist只需要修改要插入位置前节点的尾指针即可
dict
结构
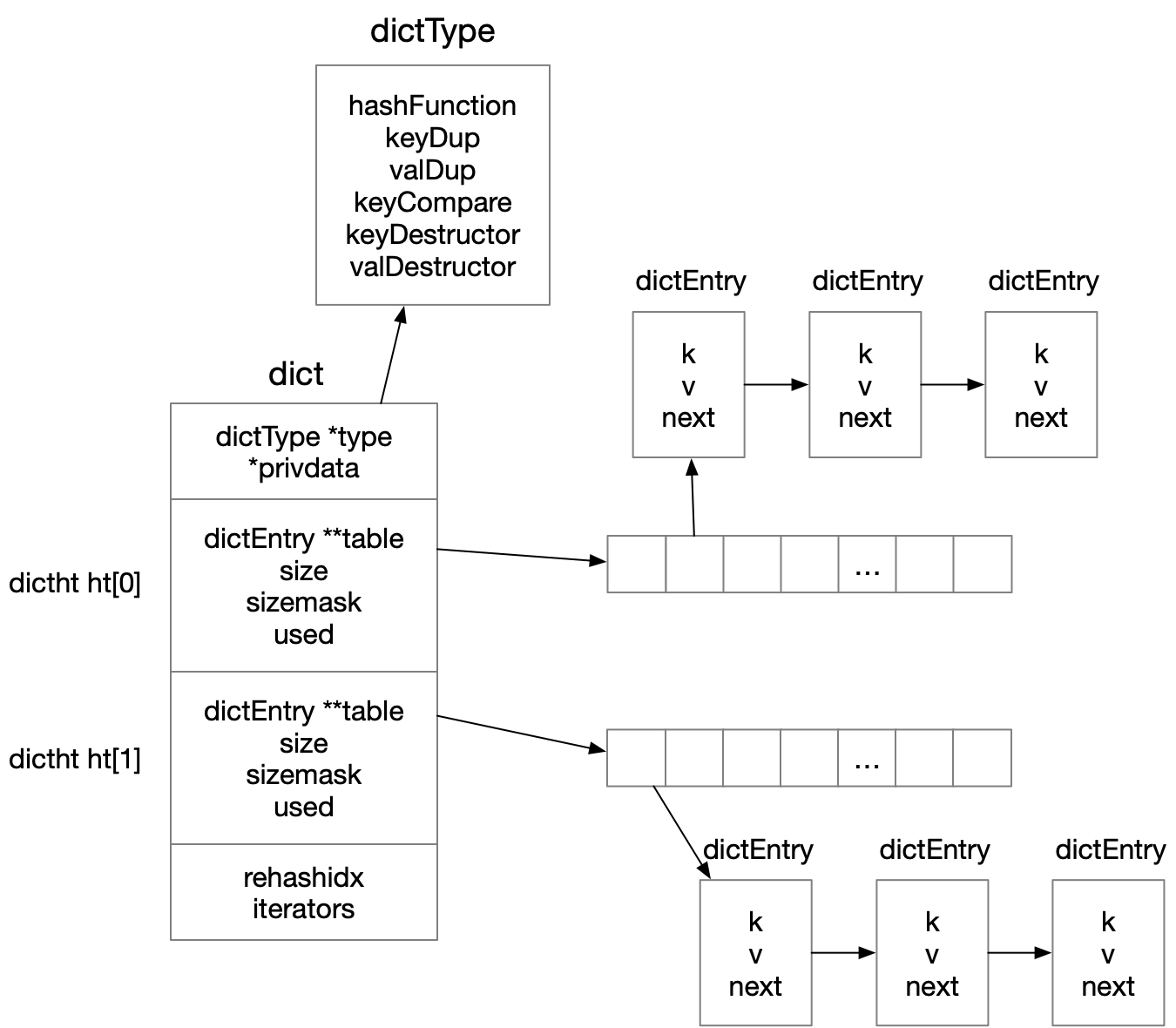
说明:
dict:
- ht[0]与ht[1]是两个哈希表,在不重哈希的时候,只有ht[0]有效,ht[1]没有数据,在重哈希的时候,ht[0]和ht[1]都有效;目的是为了当ht[0]需要扩容rehash时,不阻塞主线程(在发生rehash时,只向ht[1]中写,同时从ht[0]和ht[1]中读)
- rehasidx:-1表示没有在rehash过程,否则在进行rehash
dictType:
- hashFunction:对key进行哈希值计算的哈希函数
- keyDup和valDup:分别定义key和value的拷贝函数
- keyCompare:定义key的比较操作
- keyDestructor和valDestructor:kye和value的析构函数
dictEntry:
- k:指向key的指针
- v:直接存放uint64_t、int64_t或double类型,或者指向任意类型的指针
- next:指向下一个dictEntry的指针
ZSET的实现
- 当数据较少时,sorted set是由ziplist实现的
- 当数据多的时候,sorted set是由dict + skiplist实现的。其中,dict用来查询数据到分数的对应关系,skiplist用来根据分数查询数据(可能是范围查找)
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
当sorted set中<k,score>个数超过128时,即ziplist数据项超过256,或者,当sorted set插入的任意数据的长度超过64字节时,会将ziplist转为dict+skiplist
ZSET的操作
| 操作 | 描述 | 流程 | 时间复杂度 |
|---|---|---|---|
| zscore | 查询key的分值 | 在dict中查询 | O(1) |
| zrevrank | 查询key的排名 | 通过key在dict查到score,然后通过score在skiplist查询排名 | O(logn) |
| zrevrange | 根据一个排名范围,查询排名在这个范围内的数据 | 在扩展后的skiplist中查询 | O(log(n) + M) |
| zrevrangebyscore | 根据分数区间查询数据集合 | 在skiplist中查询 | O(log(n) + M) |