本文简述MySQL 一条更新指令的执行流程,和其中涉及的日志、crash safe策略、缓存优化方式
update涉及的日志模块
Redo log
why we use redo log?
redo log 是 InnoDB 引擎特有的日志,由于最开始MySQL没有InnoDB引擎,而MyISAM没有crash-safe能力,导致MySQL在crash时数据是不安全的(WHY?)。所以InnoDB 使用另外一套日志系统——redo log来实现 crash-safe的能力。
crash safe
如果没有redo log,只有bin log,在写bin log过程中如果服务crash,导致数据丢失
Bin log
bin log是MySQL Server层实现的,记录SQL语句的原始逻辑,bin log是追加的,不会覆盖以前的日志
redo log 与 bin log 的区别
- 实现层级不同:redo log是 InnoDB 实现的,bin log是MySQL的Server层实现的
- 记录内容不同:redo log记录数据页的修改,bin log是语句的逻辑
- 存储形式不同:redo log是循环写的,bin log 是追加写的
Update 语句执行的流程
数据页
为了避免一条一条读取磁盘数据,InnoDB采取页的方式,作为磁盘和内存之间交互的基本单位。一个页的大小一般是16KB。InnoDB主键索引B+树的叶子节点存放表中数据记录的页,称为索引页or数据页
change buffer
在更新某些记录时,先判断这些记录的数据页是否在缓冲池(buffer pool)中,如果这些页面不在buffer pool中,将要更新(INSERT,UPDATE或DELETE操作DML)操作记录到change buffer中。当读操作将页加载到缓冲池时,将数据页和change buffer合并
目的
无需从磁盘读数据页到内存,提升DML操作相应时间
merge 操作
change buffer中的操作写到原数据页的过程
merge的触发条件有:
- 有读操作访问该数据页
- 系统后台线程定期merge
- 数据库正常关闭(shutdown)的过程
何时使用change buffer
对于唯一索引,更新操作都要先判断该操作是否违反唯一性约束;比如,要插入(4,400)记录,要先判断表中是否已存k=4记录,就必须要将数据页读入内存来判断,从第一个k=4的记录开始,顺序的找到第一个k≠4的记录结束。仅写入change buffer无法判断索引的唯一性 因此,唯一索引的更新不能使用change buffer,只有普通索引可使用
为什么无索引不可以使用 change buffer呢?因为无索引则无法找到数据页(索引页)
Update执行流程
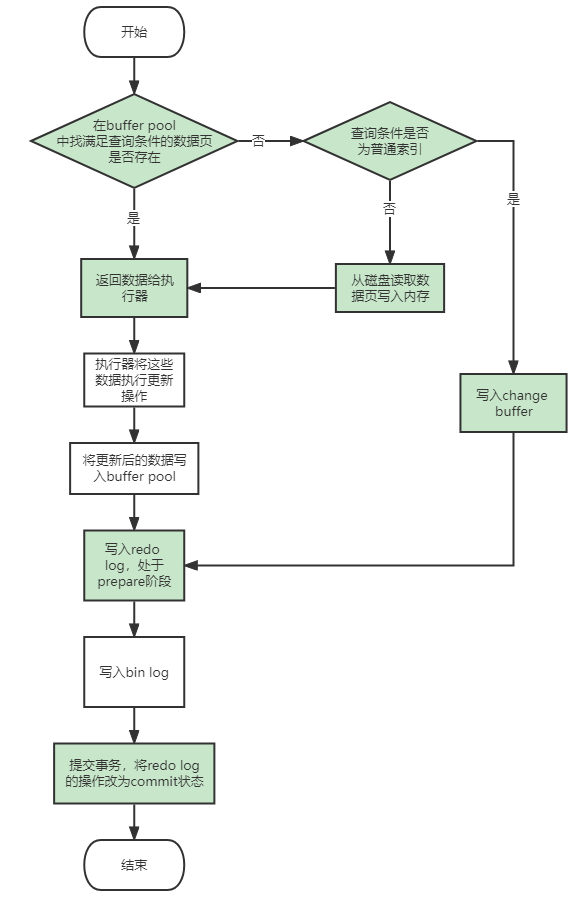
流程说明:
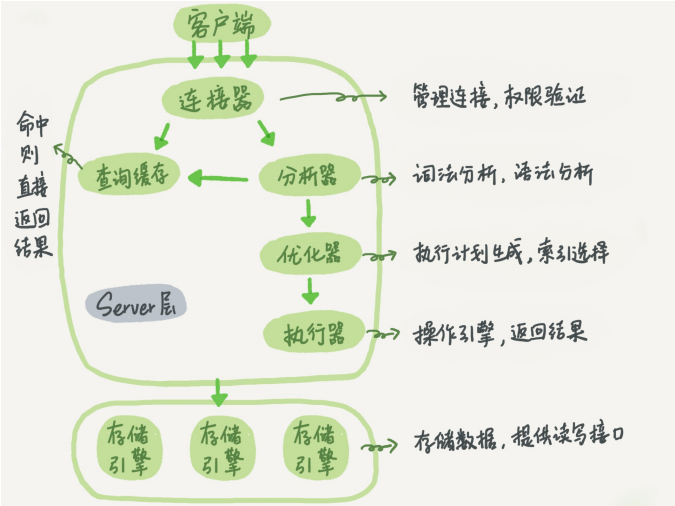
图1:同查询语句的执行流程,在MySQL的Server层,再调用存储引擎
图2:绿色部分表示在存储引擎(Innodb)中执行,白色在MySQL的Server层执行
两阶段提交
先写入redo log,再写入bin log,再将redo log的操作设置为commit状态。目的:为了保证redo log和bin log的逻辑一致
如果不使用两阶段提交会有什么问题
- 先写redolog,再写binlog: redolog写完,还没来得及写binlog,MySQL宕机。重启以后,redolog里有记录,MySQL判断事务提交成功,但binlog里没有记录,binlog与redolog出现数据不一致。由于binlog是追加写入日志,往后的时间里binlog会一直缺失这条数据。如果在以后使用binlog恢复这个时间点的数据,会出现数据丢失的情况
- 先写binlog,再写redolog: binlog写完,还没来得及写redolog,MySQL宕机。重启以后,redolog中没有记录,MySQL判断事务提交失败,但是binlog中有记录,binlog与redolog出现数据不一致。如果以后使用binlog恢复数据,就多出了一个事务操作
数据是怎么写入磁盘实际位置
单独的线程将redo log的checkpoint后的记录写入磁盘上的数据页,直到追到write pos为止,write pos 如果追上checkpoint则不能更新数据
如果write pos要覆盖之前的redo log记录,需要判断该redo log记录是否对一个事务可见,如果存在,则不能覆盖该redo log记录,判断方法:存在一个事务id,使得trx_id < 事务id

为什么不直接写到磁盘,而是通过redo log呢?是因为写磁盘是一个随机IO访问,写redo log是顺序的IO访问;即使通过索引可以找到磁盘地址,但是机械硬盘寻址也需要通过磁道旋转
当change buffer的merge操作也会将数据写入磁盘
change buffer 和 redo log 的数据都会刷到磁盘,怎么保证不相互影响呢?
脏页
- 什么是脏页:内存数据与磁盘数据不一致的内存中的数据页
- 怎么判断脏页:LSN(Page) > LSN(checkpoint)
- 什么情况会触发flush 刷脏页:1. redo log 满了;2. buffer pool 满了;3. 空闲;4. 正常关闭
- 什么情况会导致更新操作执行时间很长:1. redo log 满了;2. 需要刷的脏页太多
总结
本文描述了一条update操作执行的流程,分为MySQL的Server层,和存储引擎层;为了提高update操作执行效率,不直接将数据写入磁盘,而是写到redo log中,化随机IO为顺序IO;redo log 的另一个作用是通过两阶段提交保证 crash safe;如果数据不在innodb 的 buffer pool中,如果有普通索引,可以不将数据页读到 buffer pool,而是将变更操作写入 change buffer,减少数据从磁盘拷贝到内存的过程;数据写入redo log后,会有单独线程flush到磁盘;数据页的数据在内存与磁盘不一致时,称该数据页为脏页,一定条件需要刷脏页,可能导致更新操作执行时间很长。