本文介绍大模型应用中常用的技术,你可以了解到大模型应用的一整套运行机制及其原理
前言
在介绍前,先明确两个概念:
- 大模型(Large Language Model - LLM):是一个经过海量数据训练的概率预测模型,核心能力是根据给定的上下文,预测下一个最可能出现的词,通过不断重复这个过程来生成内容。常见的大模型如 gemini-2.5-pro, qwen3-235b-a22b, gpt-4.1-mini
- 大模型应用(LLM Application / AI Agent):利用一个或多个大模型作为核心引擎,为解决特定任务构建的软件产品或服务
例如,我们访问 https://www.deepseek.com/ 网页,这是一个大模型应用,应用内部调用了若干个 deepseek 模型,可能是 DeepSeek-V3.1、DeepSeek R1 等
如果我们想自己构建一个大模型应用,可以将大模型下载在自己的机器上私有化部署,或者直接调用模型厂商的 openapi 访问公有云模型,然后在模型上层,搭建与用户交互的网页、app
区分这两个概念很重要,本文所讲的,都是 大模型应用 的内容,不涉及大模型本身
下面表示了大模型与大模型应用的关系,以及下文即将介绍的一些重要概念
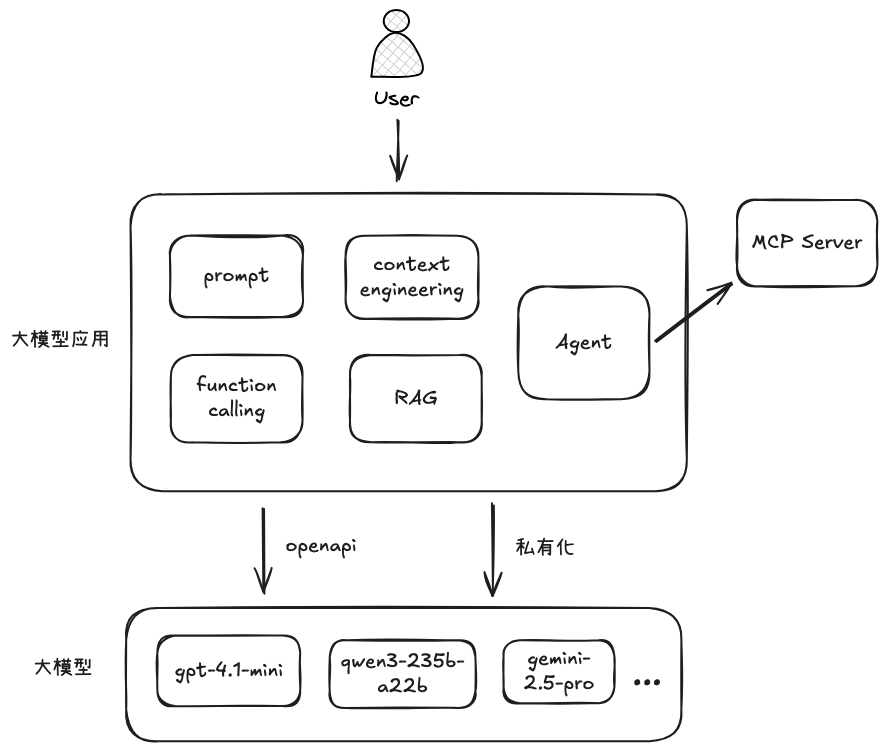
下面我们对大模型应用中的概念依次介绍
Prompt
用户提示词 & 系统提示词
提示词(Prompt)是输入给大模型的指令或问题,分为两类:
用户提示词(User Prompt):由用户在对话框编写的输入给大模型的指令或问题
系统提示词(System Prompt):由应用开发者设定,用来确定大模型的身份、行为准则、输出格式;与用户提示词一起发给大模型
常见的系统提示词有:
- 角色设定:你是一个计算机领域的专家
- 行为规范:请使用中文,可爱的喵语回答
- 输出要求:以 json 格式返回结果
系统提示词一般由大模型应用生成,有的应用提供了页面编辑系统提示词
当然如果用户主动输入系统提示词的文字也可以达到一样的效果,只不过一般用户不会这样做
下面我们通过几个例子看下提示词对生成结果的影响
只有用户提示词的例子
1 | prompt = [HumanMessage(content="苹果的英文怎么说")] |
回复:苹果的英文是 apple
有系统提示词的例子
1 | prompt = [ |
回复:喵~苹果的英文是 "apple" 喵!就像小鱼干一样好吃喵~🍎
通过系统提示词,可以让答案具有我们希望的风格、格式,更好满足不同场景的需求
当有很多场景,每次场景都系统提示词类似,例如:
美食领域:你是一位资深厨师,请用专业详细的方式解释如何制作意大利面。要求分步骤说明,包含关键技巧和常见错误避免;
计算机领域:你是一位资深软件开发工程师,请用专业详细的方式解释 JVM 的运行原理。要求分步骤说明,包含关键技巧和常见错误避免;
...
硬编码提示词就会难以维护,可以通过提示词模板来解决这个问题
提示词模板
提示词模板(Prompt template)是一个预先设计好的包含变量的提示词结构,在运行时填充具体值。示例如下:
1 | from langchain.prompts import PromptTemplate |
这样很多场景可以共用一个提示词模板,利于维护
如果是通用问答系统,怎么确定用户问题与提示词的关系呢?
上面的提示词都是明确给出系统设定,我们还可以在提示词中填充答案示例(少量样本),让大模型参考
少样本学习
少样本(Few-Shot 学习)是通过少量示例让大模型学会新任务的技术,主要用处有:
复杂任务分解
希望模型输出一些中间思考的过程,而不是一口气把答案返回
适配特定领域
如教客服机器人处理不同类型的问题,给出人工客服回复的示例,让机器人回复符合规范
1 | customer_service_examples = [ |
Few-Shot 可以让大模型参考示例给出答案,适用于任务简单明确、有 2-5 个清晰示例、需要特定输出格式的场景
下面来看一个完整例子
1 | from langchain.schema import HumanMessage, SystemMessage |
回复:
是否需要后续问题:是 后续问题:康熙在位多少年? 中间答案:康熙在位61年 后续问题:乾隆在位多少年? 中间答案:乾隆在位60年(实际掌权时间,不含太上皇时期) 所以最终答案是:康熙的在位时间长于乾隆
提示词小结:
- 提示词可以给模型设定角色、规范,让答案更符合期望
- 提示词模板可以帮助我们维护多个场景的提示词
- 在提示词中设置少量样本可以让模型学习、参考样本回答
Function Calling
传统大模型无法直接访问实时数据或执行计算(如查询当前天气、调用支付接口等),存在一定局限
Function Calling 让大模型能否触发外部函数或工具,来扩展其能力
执行流程:
- 用户输入:如明天北京天气如何
- 函数选择:根据输入和预定义的函数列表,判断是否要调用函数,要调用哪个函数
- 生成参数:根据输入和函数预定义的参数结构,生成参数
- 执行:将生成的参数传递给函数,执行函数
- 观察:获取函数执行结果
- 循环:将结果返回给模型,模型根据结果决定下一步(继续调用函数 或 给出答案)
- 结果整合:将函数结果整合到回复中
下面我们实现一个简单的 function calling
1 | from langchain.schema import HumanMessage |
运行结果:
1 | 调用函数: get_weather |
代码说明:
- 首先我们创建了一个方法集合,集合定义了若干方法结构(方法名、描述、参数)
- 将问题和方法集合第一次请求大模型,让大模型根据问题和方法描述选择合适的方法,再根据方法参数生成请求参数
- 根据第一次请求结果:调用函数名、请求参数,本地执行函数
- 根据执行函数结果,构建提示词 prompt
- 将提示词再发给大模型,生成最终答案
这是只需一个函数的简单任务,实际的问题往往需要多个函数,这就需要应用程序与大模型多次交互完成多轮 函数选择 -> 执行 -> 构建提示词 -> 请求模型 的过程,每轮的函数结果都追加到提示词中,最终的提示词会包含所有需要执行的函数结果,一起发给大模型获得最终答案
为了体现 function calling 的流程,没有直接使用 langchain 的 tool 工具
可以发现上面的流程是很繁琐的,开发者需要维护整个循环过程和上下文,langchain 可以帮开发者实现这个过程来简化开发
function calling 是与大模型应用耦合的,由应用开发者预先定义在应用中,应用使用者无法通过 function calling 的方式调用自己的方法,比如我想让大模型帮我查询本地数据库并生成图表,应用内部肯定是没有这个方法的。下面介绍一种与大模型应用解耦的函数调用方法,让大模型也可以调用使用者提供的函数
MCP
MCP(model context protocal)模型上下文协议,是一个开放标准协议,让任何客户端都能以安全、统一的方式接入任何外部数据源、API 或工具
可以把它想象成 AI 世界的 USB 标准,让你的电脑通过 USB 链接任何键盘、鼠标、硬盘等外设一样,MCP 能够让 AI 大模型连接数据库、API服务等任何工具
为什么需要 MCP,MCP 解决了什么问题?
在没有 MCP 之前,大模型使用外部工具面临以下几个问题:
- 紧耦合与重复开发:每个大模型都要自己单独开发集成功能,功能被限制在单个大模型应用内
- 有限的工具集:用户只能使用应用预先内置的工具集,无法根据自己特定的需求进行扩展
- 安全隐患:直接让大模型访问敏感数据缺乏安全控制
MCP 就是来解决上述问题:
- 解耦:将工具提供者(MCP 服务)与工具使用者(大模型应用)分离
- 标准化:定义了一套通用的通信协议,任何遵循该协议的工具都可以被支持 MCP 的客户端使用
- 安全控制:工具运行在单独的服务器中,与大模型应用隔离,更好做权限管控
- 无限扩展:任何人都可以为他们需要的工具或数据源编写一个 MCP 服务,自主扩展大模型的能力
一个 MCP 服务一般提供两种能力:
- 资源:如文件、网页内容、数据
- 工具:执行操作的函数,如运行代码、发送邮件、科学计算等
MCP 与 Function Calling 的区分
| Function Calling | MCP | |
|---|---|---|
| 本质 | 一种模型能力 | 一个开放协议 |
| 范文 | 单个应用内部 | 跨应用调用 |
| 解决问题 | 模型选择、如何调用函数 | 函数与应用解耦 |
| 比喻 | 给模型一本说明书 | 一个所有模型都能用的工具商店 |
下面简单写一个 MCP Server 看下如何使用:
第一步:编写 MCP Server 代码
下面是一个 demo,@mcp.tool() 声明了这是一个 mcp server 方法
方法注释为大模型提供了使用说明
依赖安装参考:https://modelcontextprotocol.io/docs/develop/build-server#quick-examples
1 | from mcp.server.fastmcp import FastMCP |
第二步:注册 map server
1 | { |
这样就完成了一个 MCP Server,让我们在 Cline 上调用一下
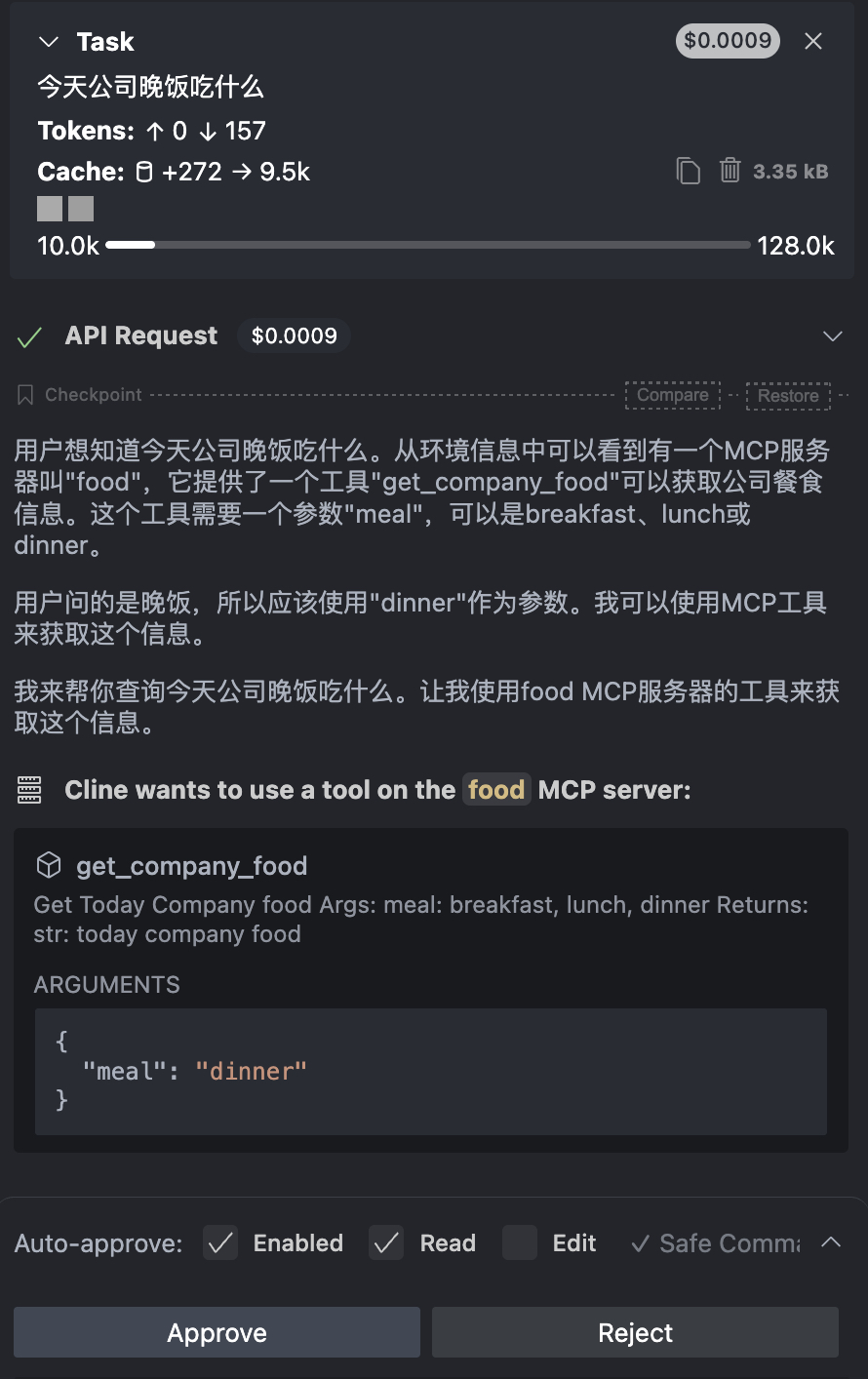
向大模型提问:今天公司晚饭吃什么
大模型从配置中读取并匹配到合适的 MCP 服务 food,根据函数注释找到参数的可选值,根据用户问题构建请求参数,在调用前请求用户授权
我们点击 Approve 允许大模型调用 food,获得 response:hot pot,返回答案:今天公司晚饭吃火锅
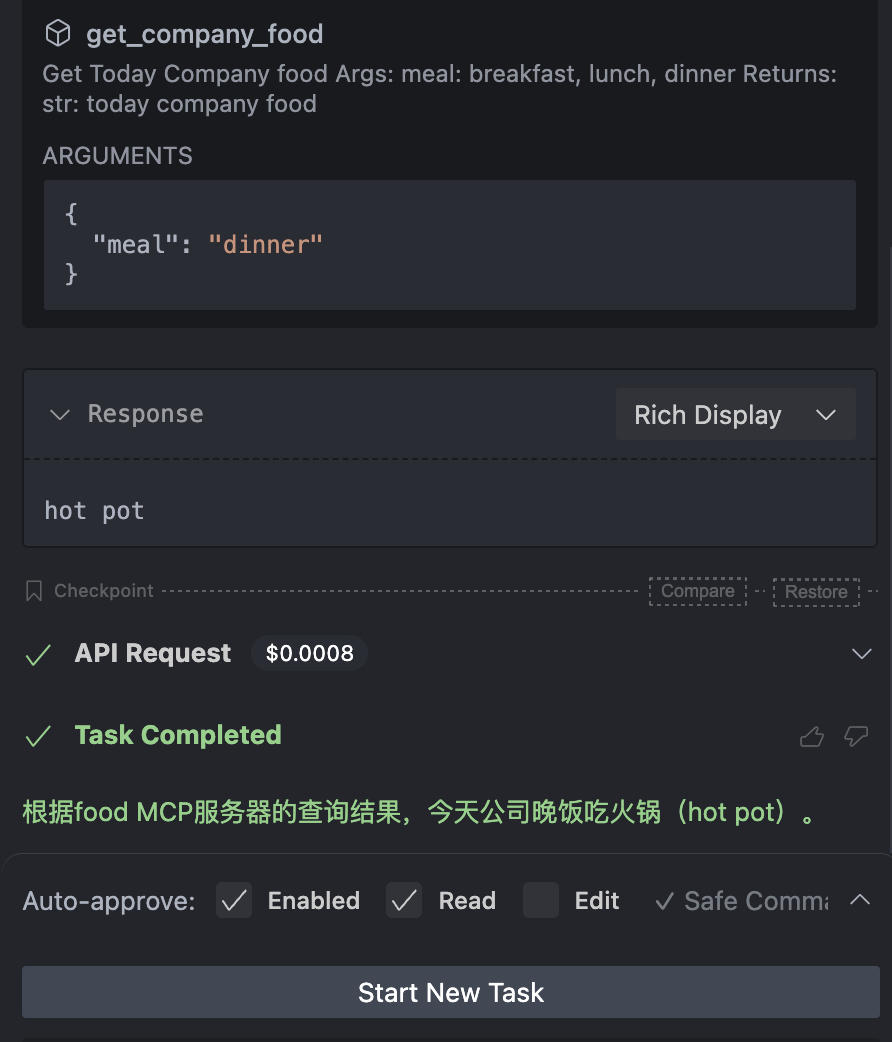
这样我们完成了 MCP Server 与大模型的交互,调用函数与大模型应用解耦,实现了模型应用外部方法的调用
还可以再 MCP 的「应用市场」上安装第三方提供的 MCP Server,实现无限扩展与资源共享
Context Engineering
上下文(Context)是模型在生成下一个词时能看到和考虑的所有文本信息总和。包含了用户提示词、系统提示词、历史对话,以及模型自己之前生成的所有回复
模型处理的上下文大小,用 token 来统计,token 是模型用来表示自然语言文本的基本单位,通常 1 个英文字符 ≈ 0.3 token,1 个中文字符 ≈ 0.6 个 token。模型单次能处理的上下文上限叫做上下文窗口(Context Window),如 GPT-4 支持 8k 和 32k token 的 Context Window,Claude 2.1 支持 200k token 的 Context Window,如果上下文超过了 context window,上下文就会被截断,可能导致关键信息丢失
扩大 context window 并非易事,主要面临两大挑战:
- 计算复杂度:模型处理长序列所需的计算资源(内存和算力)会随着令牌数量的增加呈平方级增长
- 性能衰减:即使技术上将窗口扩得很大,模型也常常无法有效利用窗口中间部分的信息,注意力更多地集中在开头和结尾
所以在每次交互中,需要管理 context window 不超出限制,且把更有价值的信息传给 LLM,这就是 Context Engineering 要做的事情
Context Engineer:上下文工程,是指为了达到特定目标,策略地管理上下文窗口的技术
类比操作系统,LLM 就像 CPU,context window 就像 RAM,限制了 LLM 单次处理的容量,正如操作系统会管理 RAM 一样,Context Engineering 管理 Context Window 的内容
为什么需要上下文工程?
- 高效利用上下文窗口:上下文窗口大小固定,需要放入最有价值的信息
- 实现复杂应用:智能体(Agent)在执行复杂任务时,往往需要多轮推理或调用工具,上下文体积会快速膨胀,可能超出模型限制
- 提高输出质量:通过提供更相关、结构化的背景信息,可以提高答案的准确性、相关性
相关的方法:
- 保存:将用户历史对话、工具调用结果保存到内存或磁盘(记事本)
- 选择:从记事本中选择与本次对话相关的内容放到 Context 中
- 压缩:Context 超过一定大小进行压缩
- 隔离:不同 Agent 的 Context 相互独立
其中,选择 Context 最常用的技术就是检索增强生成 RAG
RAG
检索增强生成 Retrieval-Augmented Generation
为什么需要 Rag
通用大模型在实际业务场景中,存在以下问题:
- 知识局限性:大模型训练数据基于网络公开数据,缺少实时性、非公开的数据
- 幻觉:缺少专业领域数据,导致大模型输出错误的答案
一个解决方案,是每次将问题和专业文档一起输入给大模型,让大模型在专业文档中找出答案,但这会带来新的问题:
- 如果专业文档字数太多,超过模型的上下文窗口(Context Window)大小,模型无法读取所有内容
- 输入内容杂乱会有噪声,干扰模型理解
- 增加推理成本,回答速度慢
相比于直接将文档丢给模型,只把文档中与问题相关的部分丢给模型更有效,比如我们想查询一个词的含义和用法,我们不是把一本字典丢给模型,而是把字典中带有这个词的部分发给模型
Rag 的工作原理
- 数据准备阶段:在用户提问前,对专业文档预处理,分为:
- 分片(chunking):将文档切分成多个片段文本
- 索引(indexing):通过 Embedding 将片段文本转化为向量,再将向量和片段文本以 k-v 对的形式存在数据库中
- 回答阶段:
- 召回:搜索与用户问题相关的片段文本(通过计算向量相似度)
- 重排:对召回的结果重新排序,找到最相近的 n 个片段文本(通过 cross-encoder)
- 生成:将用户问题(用户提示词)和重排的 n 个片段文本(系统提示词)发给大模型
下面对这几个步骤补充说明
| 步骤 | 说明 |
|---|---|
| 分片 | 简单的分片方法,如按固定长度分片,按标点、段落分片 高级的分片方法,如语义分片 |
| 索引 | 选择合适的 Embedding 模型和向量数据库来构建文档索引,key = 向量,value = 片段文本 |
| 召回 | 1. 将用户问题通过 Embedding 模型转换为一个查询向量 2. 在向量数据中使用近似最近邻(ANN)算法,快速找到与查询向量最相似的 k 个片段向量(如 k=100) 3. 返回这 100 个对应的原始文本片段 注意:要使用同一个 Embedding 模型处理问题和片段文本 |
| 重排 | 召回像是海选,从成千上万的片段中快速选出 100
个看起来符合条件的候选人,追求高召回率 重排是面试,对 100 个候选人进行更严格的评估,选出最顶尖的 n 个(如 n = 5),追求高准确率 一般使用交叉编码器(Cross-Encoder)模型,计算速度慢,但准确率高 |
| 生成 | 大模型根据重排片段文本和问题生成答案 |
很多应用支持了 RAG,如 ima - 腾讯 AI 工作台,用户可以将微信公众号文章、网页、本地文档上传到 ima 知识库,再用 deepseek 回答问题。ima 中的 RAG 程序将用户知识库检索出问题相关的片段和用户问题一起发给大模型生成答案,从而满足用户在专业领域的问答需求
Agent
Agent(智能体)是一个能感知环境、自主分析、做出决策、执行动作以实现特定任务的系统
为什么要有 Agent
从 Chat 到 Do 的转变
大模型传统的 Chatbot 模式,是一个只有大脑,没有手脚的机器人,它可以给你问题的答案,但不能帮你去做事情,具体来说,Chatbot 模式有以下问题:
- 无法感知外界:模型的知识是静态的,可能是过时,会产生幻觉
- 无法改变外界:模型可以帮你写一封邮件的内容,但最终需要你自己动手复制、粘贴、发送
- 无法处理复杂任务:很多现实任务涉及多个步骤,大模型往往需要用户介入和引导,无法自动分解子任务并逐一完成
Agent 就是在大模型基础上解决这些问题
一个简单的比喻:大模型是一本百科全书,你需要自己去翻找和组合信息;Agent 是一个全能的助理,你负责下发任务,Agent 来帮你完成任务
Agent 的组成部分
- 大脑(LLM):负责思考(Thought),包括:理解用户指令、进行逻辑推理、分解复杂任务、制定分步计划(Plan)并在每一步进行思考(Chain of Thought)
- 工具使用(Tool Use):负责行动(Action),调用各种工具执行动作
- 记忆(Memory):
- 短期记忆:记录当前会话的上下文和交互历史,以便连贯地对话
- 长期记忆:将过去任务中学到的东西存储和检索出来,用于未来的任务,实现学习和进步
ReAct 模式
ReAct(Reansoning And Action)是 Agent 的一个实现方案,它将 Reasoning(推理)和 Action(行动)结合,让 LLM 能否以交替的方式思考和执行动作,从而解决需要多步推理与外界交互的复杂任务
在 ReAct 之前,LLM 应用的主要有两种模式,各有其局限性:
- 仅推理:让模型一步步思考给出最终答案,缺点是无法获取外部信息、无法修改外部系统
- 仅行动:直接让模型调用工具执行动作,缺点是缺乏思考,容易在复杂任务中做出错误的决策
ReAct 将两者结合,其工作流程是:
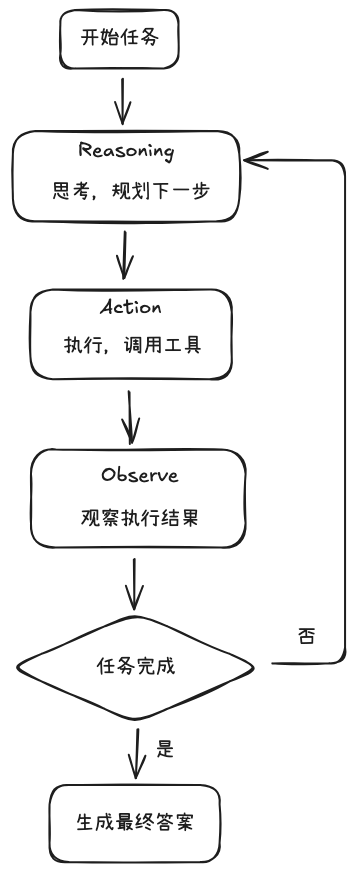
说明:
- 第一步:将用户提示词发送给 LLM,LLM 返回下一步要调用的工具、调用参数
- 第二步:通过 function calling 或 MCP 调用外部工具
- 第三步:将工具执行结果作为 系统提示词 和 用户提示词一起返回给大模型,大模型观察执行结果
- 大模型分析任务是否完成,如果未完成,重复1-3步
- 如果完成,生成最终答案
可以试着自己实现一个简单的 ReAct 模式的 Agent,其中涉及的技术包括 prompt、function calling、MCP、管理上下文,还可能用到 RAG 等等,看起来工作量还是很大的,有什么框架帮我们实现了这些,从而快速搭建一个 Agent 呢?
大模型应用框架
LangChain
https://python.langchain.com/docs/introduction/
LangChain 是一个用于开发 大模型应用 的框架,极大简化了大模型应用的开发、部署、生产
我们主要开发阶段,LangChain 提供了哪些组件帮助搭建大模型应用
LangChain 组件
https://python.langchain.com/docs/how_to/
Chat models
集成了市面上流行的大语言模型,方便创建和调用
1 | gpt_4o = init_chat_model("gpt-4o", temperature=0) |
Messages
封装了模型的输入/输出,如:
1 | SystemMessage: 系统提示词 |
Prompt template
提示词模板,用于构造提示词、Few-Shot Examples 等
1 | prompt = PromptTemplate( |
1 | from langchain_core.prompts import PromptTemplate |
Examples selectors
示例选择器:根据用户输入,从一堆示例中挑选出最相关的几个,用于提升 Few-Shot Learning 的效率和效果
1 | examples = [ |
LLMs
旧的 LLM 模型,输入和输出都是字符串
Output parsers
模型输出解析器,解析为希望的结构化格式
Documnet loarders
文档加载器,用于加载 PDF、网页、CSV、Json、Markdown 等文档
1 | from langchain_community.document_loaders import PyPDFLoader |
Text splitters
文本拆分器,用于将文档拆分成可用于检索的块(chunks)
1 | from langchain_text_splitters import RecursiveCharacterTextSplitter |
Embedding models
嵌入模型:将文本通过嵌入模型转化为向量
1 | from langchain_openai import OpenAIEmbeddings |
Vector stores
将向量存储到向量数据库
Retrievers
检索:负责检索相关的文档,如在向量数据库中检索文本块
Indexing
用户数据源发生变化时(如网站、PDF 更新)避免全部重建索引,增量更新索引
通过 LangChain 的这几个组件,可以帮助我们实现 RAG 的全过程
- Document Loaders 来加载文档
- Text Splitters 分割成片段
- Embedding Models 将文本片段转为向量
- Vector stores 将向量存储到数据库
- Indexing 来维护向量与文本的映射关系
- Retrievers 负责在向量数据库中检索相关片段
Tools
创建工具,供大模型外部调用
1 |
|
Multimodel
多模态组件,让 langchain 支持处理文本、图片、视频等多种类型的信息,输入给多模态 LLM
Agents
用 LangChain 实现 Agent,现在推荐使用 LangGraph
Callbacks
Callbacks 是 LangChain 的观测组件,允许你在应用程序执行的各个关键阶段(如 LLM 调用开始、结束时)注入自定义逻辑的 Hook,用于日志记录、监控、调试、流式传输等目的
Custom
自定义组件让开发者可以扩展 LangChain 组件
Serialization
将 LangChain 对象持久化保存和加载
LangGraph
LangGraph 是由 LangChain 团队开发的,用于构建复杂的、有状态的、由多个链或循环组成的大模型应用,它擅长处理需要多次调用 LLM、工具等步骤,并且这些步骤之间存在复杂依赖关系和状态传递的场景
为什么需要 LangGraph
用 LangChain 构建大模型应用,是一个预定义好步骤的链,比如:
- 用户输入一个问题
- LLM 决定需要用什么工具来回答
- 调用那个工具
- 将工具结果返回给 LLM 生成最终答案
但是标准链有一个局限性:它是单向、线性的,对于需要循环或根据中间结果反复执行某些操作的复杂任务,链就无法实现了
当然开发者可以根据 LangChain 链中某个节点的返回,自行用 if/else 和 while 循环调用不同环节,手动在各个节点间传递变量,这本质上就是开发者自己在 LangChain 之上重新实现状态机和循环逻辑
LangGraph 为了解决这个问题,引入了循环和状态的概念,使工作流可以根据条件决定下一步去哪,包括循环到之前的步骤
LangGraph 的核心概念
- 状态(State):一个字典,整个工作流的记忆中心
- 节点(Node):执行单元,比如调用一个 LLM、工具、执行代码、更新状态等;每个节点以整个状态作为输入,输出更新后的状态
- 边(Edge):控制流,决定下一步该执行哪个节点,根据状态中的某个值,动态决定下一个执行的节点
可以通过这个代码示例看下 LangGraph 是如何运行的:Agentic RAG
LangChain 与 LangGraph 对比
| LangChain | LangGraph | |
|---|---|---|
| 执行模式 | 链(Chain):将多个组件(模型、工具)按预订顺序连接起来,形成一个链式的执行流程 | 图(Graph):将多个节点(智能体、工具、逻辑)连接成一个有向图,通过循环和条件分支来控制流程 |
| 状态管理 | 隐式:状态通常在链的各个步骤之间通过传递,没有内置的、统一的状态管理机制 | 显示:使用一个共享的状态(State) 对象在整个图中传递和修改数据,管理复杂状态非常清晰 |
| 控制流 | 线性为主:主要是「开始 -> 步骤A -> 步骤B -> ... -> 结束」的线性流程 | 任意流程:支持循环和分支,容易实现「Agent 执行工具 -> 检查结果 -> 再次执行」的 ReAtc 模式 |
| 设计初衷 | 为常见的 LLM 应用提供一套标准化、可复用的组件和模块 | 为构建多智能体(Multi-Agent) 系统和有状态的、长时间运行的复杂工作流而设计 |
下图为 LangChain 和 LangGraph 实现的 Retrieval Agent 的主要流程,最大的区别是,LangChain 直接将检索结果返回,LangGraph 会对检索结果会重新提问,循环检索过程,直到认为得到了充分的答案(这个过程是不是有点像深度思考🤔)
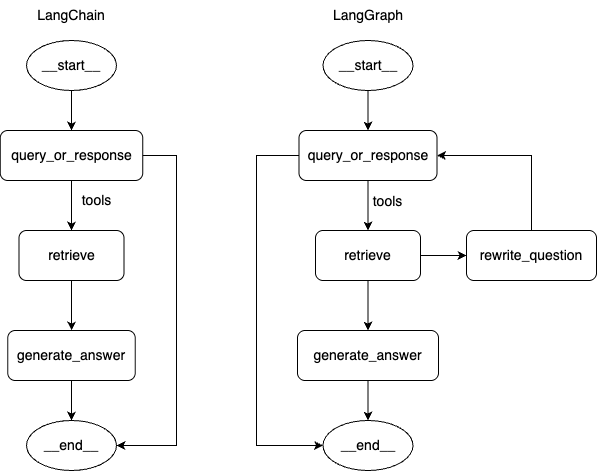
两者的关系:
LangGraph 是在 LangChain 之上的一个高级扩展,复用了很多 LangChain 的核心组件,专门解决了 LangChain 不擅长的复杂流程问题
总结
本文介绍了大模型应用中的几个重要技术:Prompt、Function Calling、MCP、Context Engineering、RAG、Agent;为了方便实现这些技术,快速搭建一个大模型应用,介绍了两个框架:LangChain 和 LangGraph
Reference
https://blog.langchain.com/context-engineering-for-agents/