Raft 是一种分布式一致性算法,解决的是分布式系统中如何实现一致性的问题;在很多分布式服务中都使用了 Raft 算法,如分布式协调服务 etcd、consul,分布式数据库 TiDB,分布式消息队列 RocketMQ
下面介绍下 Raft 的核心思想和工作流程
分布式一致性问题
什么是分布式一致性问题?有什么难点呢
分布式一致性问题是在分布式系统中,多个节点在不可靠的网络环境下,对某个状态达成一致的问题。一致性问题分为两种:
即时一致性问题
假设当前集群有 master 和 follower 两个节点,Client 向 master 写入 x = 3,Client 查询 x 的请求打到 follower,如果 master 的 x = 3 已经同步到 follower,Client 可以读到 x = 3,如果同步没有到 follower 则读不到 x = 3
顺序一致性问题
Client 向 master 依次发送 x = 3, x = 4 两个请求,master 将这两个请求顺序同步到 follower,但由于网络问题,x = 3 的数据包发生了延时,x = 4 先到达 follower,导致最后 follower 中 x = 3
为避免这两个问题,一种简单粗暴的方式是数据同步串行化:写请求达到 master 后,master 将写操作执行完,同步到所有 follower,当 master 收到所有 follower 同步成功的响应后,才返回客户端 ack。这样客户端无论请求哪个节点,读到的都是最新的数据,但显然会带来严重的性能问题
CAP 理论指出,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)最多只能同时满足两项,无法同时满足
一致性:所有节点在同一时间看到的数据完全相同
可用性:每个请求都能在合理时间内获得响应
分区容错性:系统在网络分区(节点间通信中断)时仍能继续运行
其中,CA 为单机系统,CP 强调数据一致性,会牺牲系统可用性,AP 强调系统可用性,可能存在数据不一致的情况;看起来在分布式系统中,C 与 A 无法同时满足,不过 C 与 A 并非在绝对对立面,还存在调和取舍的空间。下面要介绍的 Raft 协议就是在做这件事
核心概念
- 领导者(leader) :集群首脑,负责发起【提议、提交】被多数派认可的决断
- 跟随者(follower):对 leader 的提议、提交,candidate 的竞选做出响应
- 候选人(candidate):处于竞选流程中的临时状态,根据投票结果变成 leader 或 follower
- 预写日志(write ahead log):记录写请求明细的日志
- 状态机(state machine):节点内存储数据的介质
- 提议(proposal):两阶段提交的第一阶段,指 leader 向所有节点发起日志同步请求的过程
- 提交(commit):两阶段提交的第二阶段,指 leader 认可一次写请求已经被系统采纳的动作
- 任期(term):用于标识 leader 更迭的概念,每个任期内至多只允许有一个 leader
- 日志索引(log index):日志在预写日志数组中的位置
核心思想
多数派原则
系统的决断无需全员一致通过,多数成员达成共识即视为整个系统的答复
一主多从、读写分离
leader 负责写请求,任意节点都可以负责读请求
状态机与预写日志
状态机(state machine)是节点时机存储数据的介质,是写入动作的最后一步,读请求从状态机中获取数据
预写日志(write ahead log, wal)是通过日志的方式记录下每一笔写请求的明细,让写变更有迹可循;当一个日志达到多数派认可后,才能被提交,更新到状态机中
两阶段提交
一阶段:
- leader 收到客户端写请求
- leader 将写请求添加到本地的预写日志中,并向集群中 follower 广播这笔写请求,这个过程称之为提议
- 集群中各 follower 收到同步写请求,将写请求添加到 wal,返回 leader ack
二阶段:
- leader 收到多数 follower 的 ack,leader 会提交这个请求,并回复客户端写成功
- leader 告诉 follower(通过心跳或下一次写同步)提交动作,follower 在预写日志中提交这笔请求
可以发现,raft 的多数派原则,不再需要全员都一致,大大提高了可用性
raft 没有保证实时一致性,可能读到不一致的数据,但可以保证最终一致性,这是怎么实现的呢
领导者选举
Raft 是一主多从的架构,如果主出了问题,会导致整个集群不可写
为了解决这个问题,raft 设计了一套选举机制,如果 leader 不可用,会由 follower 补位成为新的 leader
这里存在两个问题:
- 如何感知 leader 不可用
- 怎么选 follower 成为新 leader
在 leader 健康的时候,leader 会定期向 follower 发送心跳,证明自己健康;follower 会监听心跳,如果超过指定时长未能收到 leader 心跳,则认为 leader 已不可用,然后切换成候选人(candidate)发起竞选
follower 成为 candidate 后会广播所有节点投票,当投票数达到多数派时,该 candidate 获胜,成为新 leader
如果多个 follower 都发起竞选,是否可能出现每个 follower 都达不到多数票的情况呢?
为了防止多个 follower 短时间内同时发起竞选,选举超时时间(election timeout)在每个 follower 上是一个固定的随机数(150ms ~ 300ms)
下列情况会更新 follower 的 election timeout 计时器:
- 收到 leader 心跳
- 收到更高 term 的请求
- 为其他 candidate 投票(也可以防止多个 follower 同时发起竞选)
任期
任期 Term 记录了一个 leader 的生命周期,集群由一个 leader 切换到另一个 leader,Term 会累加 1
当一个 candidate 发起一轮竞选时,会将当前 term + 1 = term_new,如果其胜出成为新 leader,term_new 就是整个集群的 term
由于在一个 term 内,candidate 需要得多数派选票才能胜出,且每个 follower 只有一票,所以最多只有一个 candidate 胜出成为 leader
不是每个 term 都会有 leader,有可能短时间内多个 candidate 同时发起选举,导致没有 candidate 获得多数派选票,这时每个 candidate 会将 term + 1,开始下一轮竞选
日志索引
节点的预写日志存放在一个数组中,每条日志在数组中的位置称之为索引 index
运行机制
了解完 raft 的核心概念和思想,看一下 raft 是如何运行的
角色职责
| 角色 | 职责 |
|---|---|
| Leader | 1. 接受客户端写请求 2. 向所有节点广播这个写请求 3. 广播心跳,心跳包带有 leader term 与最新已提交日志的 index,推动 follower 更新日志提交进度 |
| Follower | 1. 接收 leader 同步的写请求,写到 wal 2. 写 wal 后返回 leader ack 3. 接收 leader 心跳,根据 commit index 将已提交的日志写入状态机 4. 为参与竞选的 candidate 投票 |
| Candidate | 1. 发起投票,且投自己一票 2. 广播拉票 3. 拉票超时前,得到多数派票,成为 leader 4. 拉票超时前,未得到多数派票,退回 follower 5. 拉票超时前,收到更大 term 请求,说明已有其他 candidate 上位,退回 follower 6. 拉票超时,竞选任期+1,发起新一轮竞选 |
角色流转
| From | To | 触发条件 | 转换动作 |
|---|---|---|---|
| Follower | Candidate | follower 在选举超时(Election Timeout)内未收到 Leader 的心跳 | 自增 term,切换为 candidate,给自己投一票,向其他节点发起投票请求 |
| Candidate | Leader | 收到多数节点的投票(N/2+1) | 切换为 Leader,向所有节点发送心跳,开始接收客户端写请求 |
| Candidate | Follower | 收到更高 Term 的消息 或 选举超时 | 更新自身 term 为收到的更高 Term(认为已有其他 candidate 胜出),切换为 Follower |
| Leader | Follower | 收到更高 Term 的消息(由于网络问题失联后恢复发现已经开始了新一轮任期) | 更新自身 term 为收到的 term,切换为 Follower |
| Candidate | Candidate | 规定时间内没有一个 candidate 获取多数派选票 | Term + 1,发起新一轮竞选 |
工作流程
写流程
Case1:正常情况
- leader 收到客户端写请求,写入自己的 wal 数值末尾
- leader 广播向集群中所有节点发送同步日志的请求,称之为一阶段的提议
- follower 校验同步日志的合法性(term >= 自身 term,index = 自身最大 index + 1)
- follower 将日志同步到自己的 wal 数组中后,回复 leader ack
- leader 发现这笔请求的 wal 已被多数派完成同步(包括自身),提交该日志,并回复客户端写请求成功
Case2:leader 任期滞后
- follower 拒绝 leader 的本次同步,在响应中告知 leader 当前最新的 term
- leader 感知到新 term 后退位
Case3:follower 日志滞后
- follower 拒绝 leader 的本次同步
- leader 尝试向 follower 同步前一笔日志,直到补齐 follower 缺失的日志
读流程
raft 标准模型中,读请求可以被集群中任意节点处理
日志同步流程
发起人:leader
目的:leader 像其他节点同步预写日志
请求参数:
| 字段 | 说明 |
|---|---|
| term | Leader 的任期 |
| leaderId | Leader 的节点 id |
| leaderCommit | Leader 最新提交的日志 index |
| preLogIndex | 当前同步日志的前一条日志的 Index |
| preLogTerm | 当前同步日志的前一条日志的 term |
| log[] | 同步的日志,可能为多笔 |
响应参数:
| 字段 | 说明 |
|---|---|
| term | 节点的任期 |
| success | 是否同步成功 |
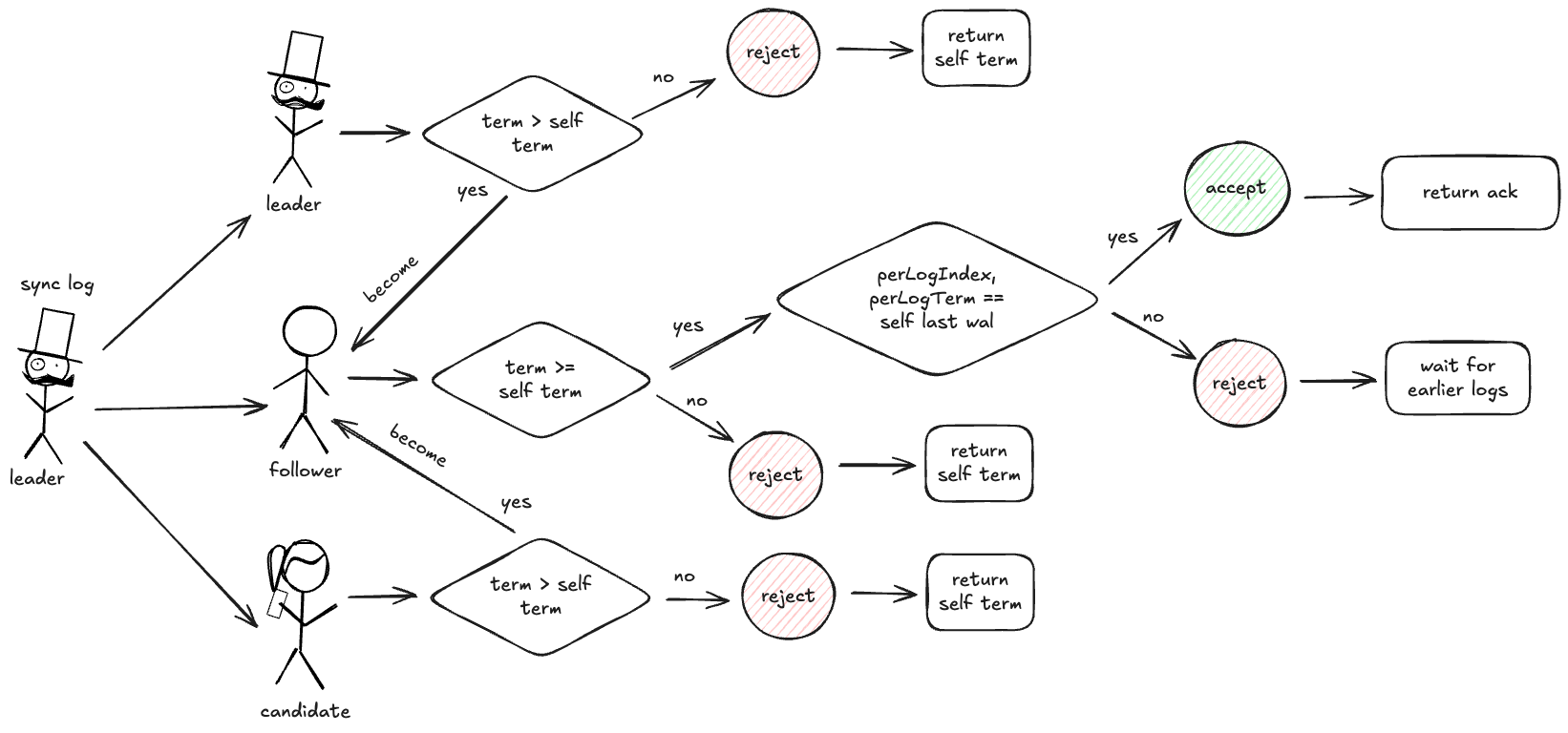
其中 follower 如果发现自己的日志落后于 leader,会拒绝请求,让 leader 重发更早的日志,直到追齐进度
如果 leader 收到多数派的同步成功响应,leader 会提交这笔日志
如果某个节点拒绝同步并回复一个更大的任期,leader 退位回 follower,更新自身 term
如果 leader 收到拒绝同步且任期相同,leader 会递归地将前一条日志和本次日志一起发给该节点,直到其接受同步
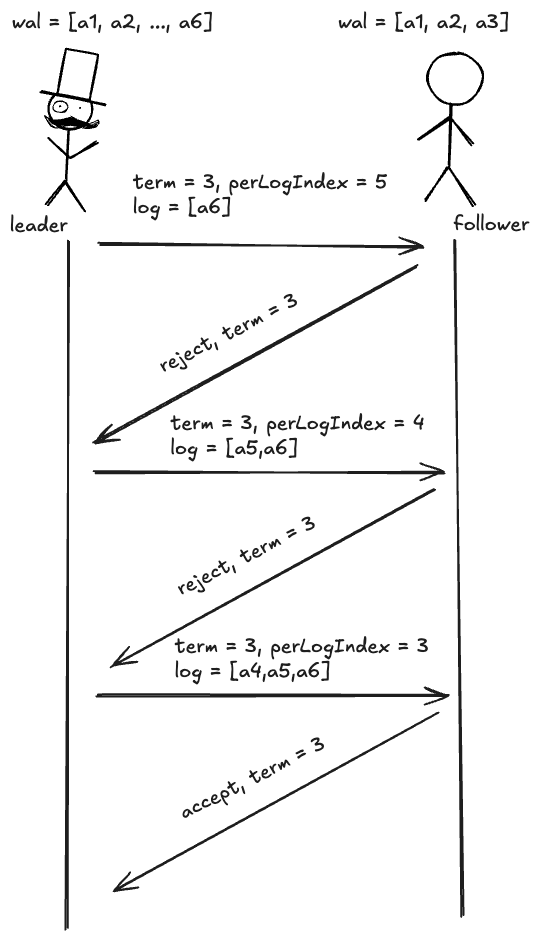
日志同步流程保证了 leader 与 follower 的预写日志的内容和顺序是一致的,保证了 leader 和 follower 数据的最终一致性
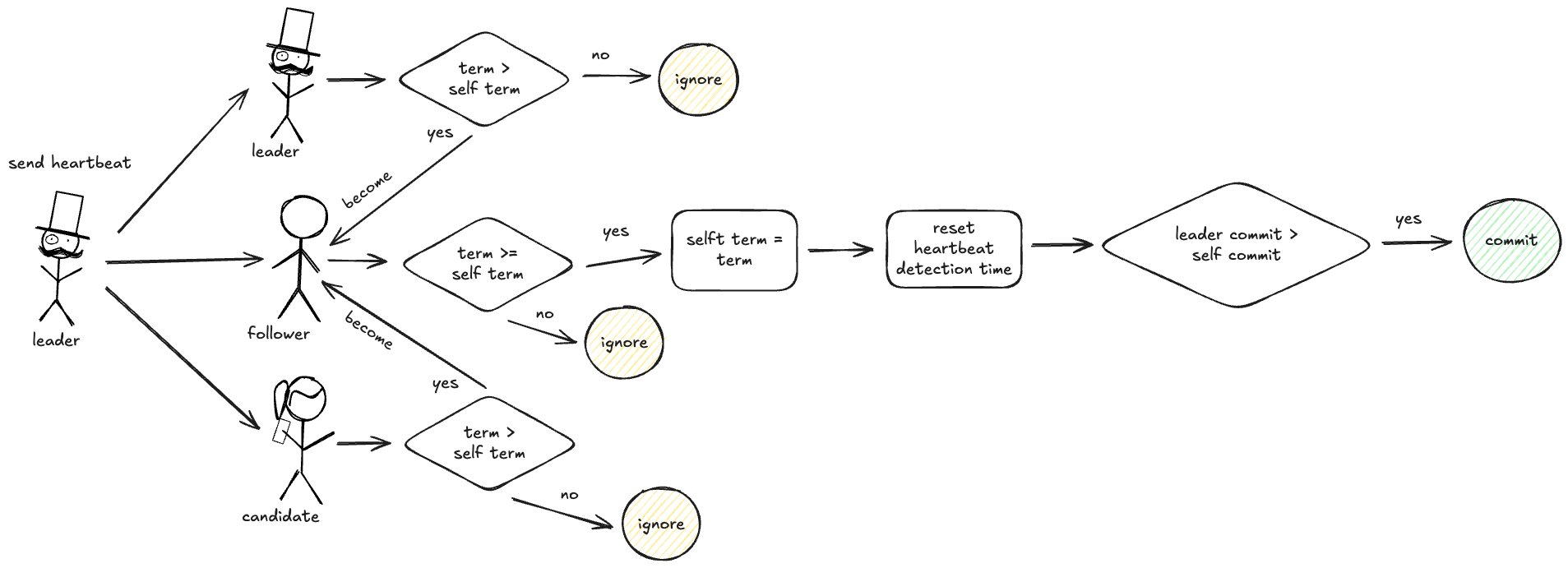
心跳&提交日志流程
发起人:leader
目的:周期性发送心跳证明自己还健在,同时提交日志进度
请求参数
| 字段 | 说明 |
|---|---|
| term | Leader 的任期 |
| leaderId | leader 的节点 id |
| leaderCommit | Leader 最新提交的日志 index,用于 follower 更新日志进度 |
竞选流程
发起人:candidate
请求参数:
| 字段 | 说明 |
|---|---|
| term | candidate 的竞选任期 |
| candidateId | candidate 的节点 id |
| lastLogIndex | candidate 最新一笔预写日志的 index |
| lastLogTerm | candidate 最新一笔预写日志的 term |
竞选成功流程:
- Candidate 发起投票,向所有节点发起请求(reqTerm, candidateId, reqLastLogIndex, reqLastLogTerm)
- Follower 收到投票请求,满足以下条件,则投票
- reqTerm 大于自身 term
- reqLastLogIndex 大于等于自身 lastLogIndex
- reqLastLogIndex 大于等于自身 lastLogTerm
- Candidate 收到投票请求,如果 reqTerm 大于自身 term,投票,回退为 Follower
- Leader 收到投票请求,如果 reqTerm 大于自身 term,投票,回退为 Follower
Follower、Candidate、Leader 投票后,会更新自身 term 为 reqTerm
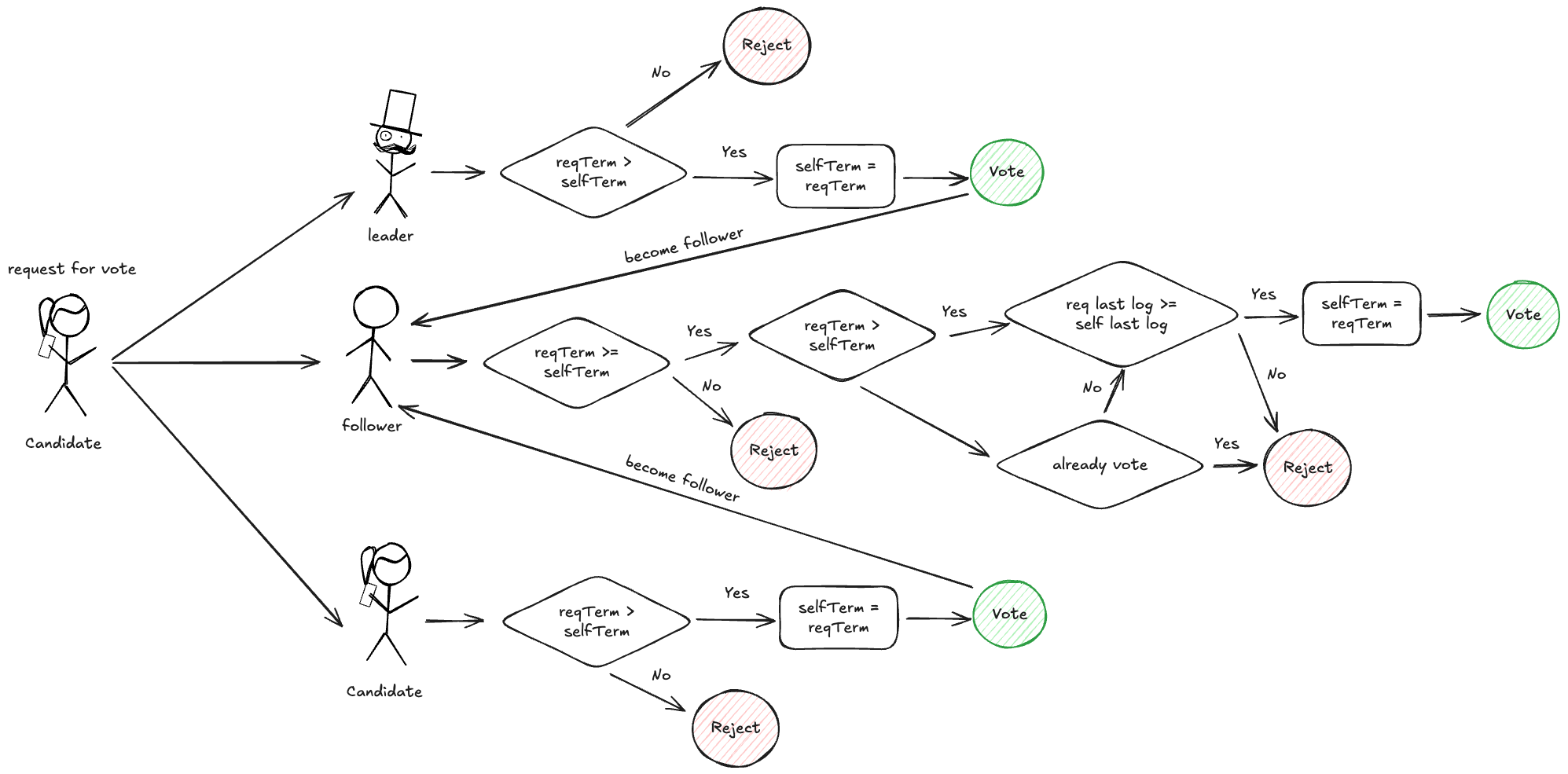
投票后 candidate 的处理:
- 如果获得了多数派的赞同票(包括自己),晋升为 leader
- 如果获得了多数派的反对票,退回 follower
- 如果反对票中出现比自己更高的 term,退回 follower,更新 term
- 如果选举过程中收到了 term 大于等于自己的 leader 请求,退回 follower,更新 term
- 如果竞选超时,自增任期,发起下一轮竞选
心跳和竞选保证了集群的高可用
总结
本文介绍了 raft 协议的概念、角色、主要流程,下面讨论几个问题
问题1:raft 如何保证最终一致性
- 各节点的预写日志的内容和顺序都是一致的(见日志同步)
- 不丢失:通过多数派原则 + ack 机制,保证日志一定存在于大多数节点上
- 不重复:节点接收日志同步具有幂等去重
问题2:raft 怎么保证数据完整性
- 有最新数据的节点才能竞选胜出成为 leader
- 如果新的 leader 发现自己存在未提交的日志,会通过一致性检查判读这条日志是否在多数派节点上,再决定是否提交
数据完整性只对于成功响应客户端的数据
问题3:为什么需要多数派原则
如果低于一半节点,比如自定义一个阈值,比如 (1/2n - 1),2/5n 会有什么问题?
这里主要是为了防止网络分区时,可能出现脑裂(多个 leader)导致数据可以提交到多个 leader,不同分区的数据不一致
比如一个集群有101台机器,分布在两个机房,机房 A 有 55 台机器,机房 B 有 46 台机器,如果机房间网络出现问题,在多数派原则下,机房 A 在选举时可以选出 leader(55 > 50),但机房 B 由于最多只能获取 46 票,无法选出 leader,保证了集群在任何时刻都最多只有一个 leader
问题4:raft 存在什么问题
- 写性能受限于 leader
- 日志复制是顺序操作,不能并行提交
故 raft 不适合高频写入的场景
写性能可以通过分片优化,比如将数据分成0-99片,一个 leader 只负责 10 个分片的数据