本文介绍增益模型 - Uplift Model
背景
目前,商家可以通过多种渠道触达用户,比如广告投放、短信推送、app内部引流 等营销手段,其背后都是有成本的;营销的目标是 在固定成本下使总产出最大化
最关键的一点是 找到一部分用户进行干预会带来最大的增量收益,带来了两个问题:
- 如果选择干预群体
- 什么是增量收益,如何计算
直观来看,当我们想给一些人发优惠券提高订单数,会选择活跃度高、历史交易多、信用良好的用户,认为这些用户会更可能使用优惠券来购买;也可以给新用户、低活用户发券,认为这些人潜力更大。如果从用户属性来划分,貌似很难,如果直接从干预结果划分,则比较简单
下面来看下从干预效果,对用户如何划分
营销人群划分
| 不干预 - 不购买 | 不干预 - 购买 | |
|---|---|---|
| 干预 - 不购买 | Lost causes | Sleeping dogs |
| 干预 - 购买 | Persuadble | Sure things |
Lost causes:无望的人,这类人干预或不干预都不会购买;
Sleeping dogs:不要惹的人,对干预反感,不干预反而会买;
Sure things:赞同的人,本来就会买,干预后表示认同,即本来就会转化的人;
Persuadble:说服的人,本来不会买,干预后购买;
可以看到,对 Lost causes、Sure things 这两类人,干预前后没有改变用户行为,干预是浪费的;对 Sleeping dogs 的干预起到了反效果,应避开这类人;对 Persuadble 的干预产生了正向效果,是真正想触达的用户,即 营销敏感人群
识别营销敏感人群,有以下好处:
- 提高营销效率:将资源集中在最可能响应的人群上,避免浪费在不敏感或自然转化的人群上
- 最大化 ROI:通过精准营销,提高转化率和收入
- 个性化营销:根据敏感人群的特征,设计更有针对性的营销策略
- 减少营销疲劳:避免对不敏感人群过度营销,降低用户反感
如何识别营销敏感人群呢,下面是个人思路
思路1:找到 干预 - 购买 和 不干预 - 不购买 的人群特征,取交集
做法:先随机选出两组人群,对组 1 干预,组 2 不干预,观察用户的购买行为,可以找到干预 - 购买的人群 A,不干预 - 不购买的人群 B,分析 A、B 人群的共同特征,就是 Persuadble 人群的特征
存在问题:A、B 两个人群不一定能得到共同的特征,且需要普遍性的特征才有意义
思路2:排除法,找到 干预 - 不购买 和 不干预 - 购买 的人群特征,不含这些特征的人群就是 Persuadble
做法:同思路1
存在问题:有些特征之间有相关的,可能两个特征分开和组合起来的效果不同
下面看下 Uplift Model 是怎么做的
Uplift Model
Uplift Model 是一种用于因果推断的机器学习模型,主要用于评估某种干预对个体行为的因果影响。
传统的因果模型,预测干预对个体行为影响的概率,可以表示为: \[ Lift = P(buy|treatment) \] Uplift Model 相比于传统因果模型,其目标是估计干预的增量效应,即干预对个体行为的净影响(增量),可以表示为: \[ Lift = P(buy\ |\ treatment) - P(buy\ |\ no\ treatment) \] Lift 是增量值,buy 是个体行为 - 购买,treatment 是对个体干预,no treatment 是不对个体干预
例如:总用户有100人,平均分为两组,一组干预,一组不干预;干预组有40人购买,不干预组有20人购买,则增量值 = 40/50 - 20/50 = 40%
如果我们只关心干预的购买率,会得到收益 = 40/50 = 80%,但这里是有水分的,因为有40%的收益不需要干预也可以获得,可以减少这部分成本
对个体 i 而言,干预对个体状态或行为会产生因果效应,即 ITE(individual treament effect),可表示为: \[ ITE_i =p(Y_i|X_i,T_i=1)-p(Y_i|X_i,T_i=0) \] Yi 表示用户 i 的行为,如购买
Xj 表示用户 i 的特征
Ti 表示对用户 i 是否有干预(1表示有干预)
ITEi 表示用户 i 在有干预和无干预的结果概率之差
这里会发现一个问题,当我们计算一个用户的 ITE 时,我们无法同时观察到该用户在干预和未干预的表现情况,无法统计概率
如果我们1-10天给用户A推了一个广告,统计用户A是否购买;11-20天没有推广告,再统计用户啊是否购买,能否得到干预和未干预购买的概率呢?
这样是不可以的,因为11-20天的行为受到了1-10天干预的影响;那如果放大时间间隔呢,这样用户特征也可能发生变化,所以在一个用户特征下,我们无法观察到干预和未干预的结果
既然我们无法对一个用户在干预和非干预下进行统计,我们可以对两个有相同特征的用户,分别干预和不干预,再进行统计。假设我们有100个用户,为每个用户生成一些标签,将具有相同标签的用户均分到a组和b组,然后对a组干预,对b组不干预,然后将所有用户的 ITE 求和,就得到干预的增量值 Lift
当用户规模很大,我们对所有用户打标分组成本很大,如果对所有用户随机分成两组,那么这两组中每个特征的用户数量近似相等,这样分组和统计就方便很多了
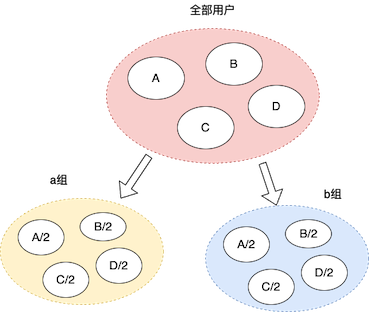
这里要注意要随机分组,来保证人群 X 与干预 T 相互独立,如果将优质用户分到 a 组,非优质用户分到 b 组,显然这样得到的结果是没有意义的
假设我们可以计算出一个用户的 ITE,那么对于任意群体,可以计算出干预对群体的平均影响,使用 CATE Conditional Average Treatment Effect 来表示: \[ 𝐶𝐴𝑇𝐸:𝜏(𝑥)=𝐸[𝑌(1)−𝑌(0)|𝑋=𝑥] \\ \] \[ =E[Y|T=1,X=x] - E[Y|T=0,X=x] \]
\[ =G(x) - P(x) \]
uplift modeling 是通过训练样本去学习不同特征 𝑋 下某个干预 T 的平均因果效应,得到一个 CATE 的评价值 𝜏 。然后通过该模型 𝜏 的泛化能力,就可以对新的个体 𝑥 预测干预效果
数据准备
做 AB 实验,将候选群体随机分成两部分:对照组 和 实验组,对照组不做干预,实验组做干预,观察一段时间内候选群体的行为;这样就得到了数据集,包括以下信息:
- 干预变量 T(1 实验组,0 对照组)
- 行为变量 Y(如是否购买,1 购买,0 未购买)
- 特征变量 X(用户特征)
模型实现
基本的 Uplift Model 有以下几种:
- 间接建模
- T-Leaner
- S-Leaner
- Class Transformation Method
- 直接建模
- Uplift Tree Model
T-Leaner
全称 Two Leaner,它分别训练两个模型来预测干预组和对照组的结果
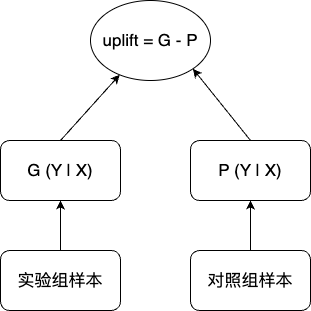
模型训练:
- 用实验组样本训练模型 G(x)
- 用对照组样本训练模型 P(X)
模型预测:输入个体特征 X,计算 G(X) - P(X) 的值,得到 X 的 CATE
我们可以定义一个阈值 beta,如果 X 的 CATE > beta,认为 X 是 营销敏感人群
优点:原理简单,思路清晰
缺点:两个模型独立,样本不共享,有误差积累,精度有限
S-Leaner
全称 Single Leaner,使用单一模型来估计干预对个体行为的增量效应
其核心思想是将干预变量作为一个特征输入模型,通过模型的预测结果来间接计算增量效应
模型训练:
- 将干预变量 T 和用户特征 X 输入模型
- 训练一个模型
\[ \hat{Y} =f(X,T) \]
模型预测:
对于每个个体,计算在干预和不干预下的预测结果,增量效应计算如下: \[ Uplift = \hat{Y}(1) - \hat{Y}(0) = f(X,T=1) - f(X,T=0) \] 优点:实现简单,适合用户特征为低维数据
缺点:
- 需要干预变量对结果影响较强
- 不适合高维度特征:如果特征变量 X 的维度较高,干预变量 T 的作用可能会被淹没在高维度中,导致模型无法捕捉干预的作用
Class Transformation Method
类别转换法(Classs Transformation Method)是一种将增量评估问题转为传统分类问题的方法,尤其适合处理二分类问题(如用户是否购买、是否点击等)
对于每个个体,定义一个新的目标变量 Z: \[ Z=Y*T+(1−Y)*(1−T) \] 其中,Y 是个体行为(如 是否购买,Y=1 表示购买,Y=0 表示不购买),T 是干预变量(T = 1 表示干预,T = 0 表示不干预)
通过 AB实验,我们对样本数据计算 Z:
- 实验组 购买的个体:T = 1, Y = 1, Z = 1
- 对照组 未购买的个体:T = 0, Y = 0, Z = 1
- 其他情况,Z = 0
可以发现,Z = 1 正好符合营销敏感人群的定义,所以识别 X 是否为营销敏感人群,就转换为:对 X 预测 Z = 1 的概率
可以表示为: \[ Uplift=P(Z=1∣T=1,X)−P(Z=1∣T=0,X) \] 模型训练:
输入:个体特征 X,X 是否被干预 T,行为 Z
输出:分类模型
模型预测:
输入:个体特征 X
输出:Z = 1 的概率
优点:实现简单,只需要训练一个模型
缺点:
- 仅适用于二分类问题
- 依赖于实验组、对照组数据分布是相似的,否则可能导致偏差
- 对噪声敏感
T-Leaner、S-Leaner、Class Transformation Method 都是 Uplift Model 的间接建模,需要计算预测的差值来间接推导增量效果,并非直接估计增量(我也不是很理解)
下面对间接模型的三种方法进行对比
| 方法 | T-Leaner | S-Leaner | Class Transformation |
|---|---|---|---|
| 核心思想 | 分别训练干预组和对照组的模型 | 将干预变量 T 作为特征输入单一模型 | 通过转换目标变量,将增量效应问题转化为分类问题 |
| 目标变量 | 分别预测实验组 Y 和对照组 Y | 直接预测目标变量 Y | 构造新目标变量 Z |
| 模型数量 | 2 | 1 | 1 |
| 适用场景 | 实验组、对照组差异较大 | 低维用户特征,干预影响较强 | 二分类问题 |
| 优点 | 简单易实现 | 简单易实现,适合低维用户特征 | 实现简单,适合二分类问题 |
| 缺点 | 误差积累 | 对干预变量依赖交强 | 仅适用于二分类问题,噪声敏感 |
下面来看几个直接估计增量的方法
Uplift Tree Model
增益树模型(Uplift Tree Model)是 Uplift Model 的一种直接建模方法,直接估计干预对个体行为的增量效应
核心思想:通过决策树的分裂准则和分裂点,最大化实验组和对照组之间的增量效应差异
增益树模型的分裂准则包括:
KL 散度 \[ KL = \sum_i p_ilog(\frac{p_i}{q_i}) \] 欧式距离 \[ Euclidean = \sum_i (p_i - q_i)^2 \] 卡方散度 \[ Chi-Square = \sum_i\frac{(p_i-q_i)^2}{q_i} \] 其中 pi 是实验组目标变量的分布,qi 是对照组目标变量的分布
通过上面准则来计算实验组和对照组之间的增量效应差异
目的是让分割后的对照组和实验组在某个行为上差异最大化
分裂点:选择某个特征的某个值作为分割条件,将数据集划分成两个子集;增益模型的分裂点选择是基于增量效应的优化
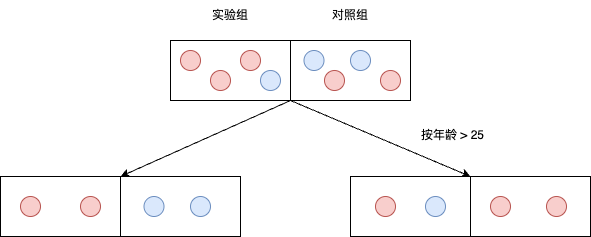
如上图,分裂点 A 为 年龄 > 25,用欧式距离作为分裂准则,计算如下:
分裂前:p0 = (0.75, 0.25), q0 = (0.5, 0.5),分裂准则 = (0.75-0.5)^2 - (0.25-0.5)^2 = 0.125
分裂后:左侧 p0 = (1, 0), q0 = (0, 1),右侧 p1 = (0.5, 0.5), q1 = (1, 0) \[ D(A) = \frac{N_L}{N}P^L(A) + \frac{N_R}{N}P^R(A) \] \[ = \frac{N_L}{N}[(p_0 - q_0)^2] + \frac{N_R}{N}[(p_1-q_1)^2] \]
\[ =\frac{4}{8}[(1 - 0)^2 + (0-1)^2] + \frac{4}{8}[(0.5-1)^2 + (0.5-0)^2] = 1.25 \]
其中,PL(A) 是用分裂点 A 分裂出的左节点的增量效应,NL 是 左节点的样本数;
分裂度量归一化
与传统的决策树分类模型类似,直接使用信息增益作为分裂标准,会偏向于选择有特征值差异大的特征,因为特征值差异大的特征有更多可能的分割点,更容易被选中,从而忽略真正有意义的特征,降低泛化能力;偏向选择特征值差异大的特征可能导致过拟合
特征值差异大的特征:在不同样本之间存在显著差异的特征,这些特征有助于区分不同类别的群体,如年龄、收入
因此,在Dgain(A) 的基础上,对『有大量差异特征值的特征』进行额外惩罚;惩罚项为: \[ Gini(A)=\frac{N_L}{N}Gini(P^L(A)) + \frac{N_R}{N}Gini(P^R(A)) \\ \] \[ Gini(P(A)) = 1-\sum^k_ip_i^2 \]
其中:pi 是当前节点样本中第 i 个类别所占的比例
假设节点 N 包含 10 个样本,一共两个类别 C、D,C 有 6 个样本,D 有 4 个样本
PC = 0.6,PD = 0.4 \[ Gini(N) = 1 - (PC^2+PD^2)=1-(0.6^2+0.4^2)=0.48 \] Gini 系统的取值范围是 [0, 0.5],当数据完全纯净时(只有一个类别),Gini = 0,类别均匀分布时,Gini = 0.5
所以,分裂点 A 的最终增量效应计算表达式为: \[ D_{gain}(A)=D(A)-Gini(A) \] 模型训练:
- 从根节点开始,选择分裂点,让分裂增益最大;用分裂点将父节点分成两个子节点
- 递归向下执行上述操作
- 剪枝,避免过拟合
常用的剪枝方法有:
- 限制树的最大深度
- 设置节点分裂所需的最小样本数
- 设置叶子节点所需的最小样本数
- 设置最大叶节点数
- 在分裂准则中加入正则项,惩罚增量效应的波动
模型预测:
- 对于每个个体,根据其特征 X 从根节点开始遍历,直到到达某个叶子节点
- 在遍历过程中,根据分裂点选择左分支或者右分支
- 到达叶子节点后,计算叶子节点的 uplift
叶结点 uplift = P(购买|干预,该叶子节点) - P(购买|不干预,该叶子节点)
优点:
- 直接优化增量效应
- 解释性强:树结构清晰,易于理解和解释
- 适合高维度数据:能否处理高维度特征和非线性关系
缺点:
- 计算复杂度高:分裂准则的计算需要较大的计算资源
- 对数据分布敏感:如果实验组和对照组的数据分布差异较大,可能导致偏差
- 容易过拟合:需要适当剪枝和正则化
工具:CausalML、EconML 等库提供了 Uplift Tree 的实现
这里只介绍一种直接建模方法,更多的方法,如 Uplift Random Forests(提升随机森林),深度学习模型 Causal Effect Variational Autoencoder 可自行了解;这里主要了解直接建模的思想,与间接建模的区别
总结
本文介绍了增益模型 Uplift model 要解决的问题、核心思想,和几种常见的模型实现
Reference
因果推断笔记(一) - Uplift Modeling with Meta-Learning Method(T-Learner/S-Learner/X-Learner)