LSM-Tree (Log-Structured-Merge Tree) 是一种用于存储键值对的数据结构,经常用于写密集型场景,广泛应用于现代键值存储系统和数据库(如 RocksDB、LevelDB 等),具有高效的写入性能和良好的读取效率
在介绍 LSM-Tree 前,先回顾下 B+树
B+树的数据结构如下:
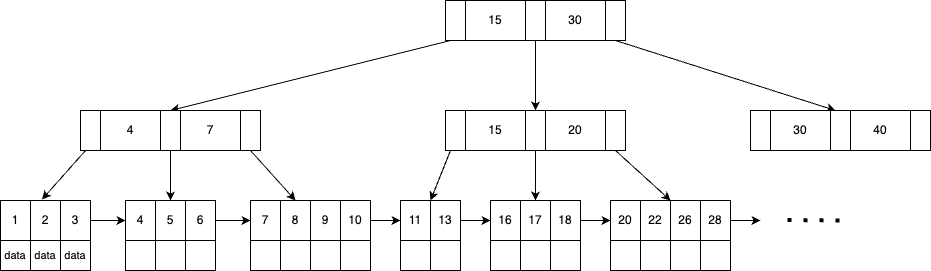
B+ 树是 MySQL 存储引擎的数据结构,B+ 树的非叶子节点只存键,用于索引,叶子节点存储键和数据(或数据指针),叶子节点相连形成有序链表
应用在 MySQL 存储引擎上有以下特点:
- 高效查询:B+树的时间复杂度为 O(log n),查找效率高
- 范围查询:B+树的叶子节点通过指针链接成有序链表,非常适合范围查询(如
BETWEEN、>、<等操作)和顺序访问 - 磁盘 I/O 次数少:B+树的节点可以存储多个键值,树的高度较低,可以减少了磁盘 I/O 次数(相比B树)
- 空间局部性:访问一个数据中,将数据所在的整个节点加载到内存中,一个节点的大小是磁盘块的整数倍。后续先从内存中访问,由于空间局部性原理,后续的访问很可能命中内存数据,减少访问磁盘次数
复杂度如下:
| 平均 | 最差 | |
|---|---|---|
| 搜索 | O(logn) | O(logn) |
| 插入 | O(logn) | O(logn) |
| 删除 | O(logn) | O(logn) |
| 空间 | O(n) | O(n) |
B+树很适合 MySQL 的查询、插入、删除等操作,B+树也存在一些问题,主要体现在以下几点:
- 插入和删除操作的复杂性:
- B+树在插入和删除数据时,需要保持树的平衡和有序性,可能会导致一些复杂的操作,如节点的分裂和合并,叶子节点内部的数据迁移;
- 插入/删除的数据一般分布在不同叶子节点上,会产生很多随机磁盘 IO
- 顺序访问的效率:虽然B+树的叶子节点通过链表相连,便于范围查询,但叶子节点之间的物理空间是不连续的,如果非常大范围的查询,需要访问大量叶子节点,仍然会产生大量随机磁盘 IO 访问
- 存储利用率低:由于主键不一定是有序递增的,每次插入数据叶子节点未完全填满,产生空间碎片
可以看出,B+树不适合 写密集型 场景。怎样设计一套适合写密集型场景的存储结构呢?
设计思路
下面设计一个适合写密集型场景的 k - v 型 存储结构
版本1:磁盘追加写
思路:顺序写比随机写在延迟和吞吐量上都有很大提升,可以将数据追加写到一个文件中
| 特性 | 顺序写(HDD) | 随机写(HDD) | 顺序写(SSD) | 随机写(SSD) |
|---|---|---|---|---|
| 延迟 | 几毫秒 | 几毫秒到十几毫秒 | 几十微秒 | 几十到几百微秒 |
| 吞吐量 | 100-200 MB/s | 1-10 MB/s | 500 MB/s 到几 GB/s | 100-500 MB/s |
| 性能瓶颈 | 磁盘转速和密度 | 寻道时间和旋转延迟 | 闪存芯片带宽 | 写放大和垃圾回收 |
写请求:将 k-v 对 和操作类型写到文件最后;时间复杂度 O(1)
读请求:从文件最后开始遍历,找到第一个 k-v 对,k = query key,如果操作类型是新增、更新,返回 value,如果操作类型是删除,返回空;时间复杂度 O(n)
优点:顺序写磁盘代替随机写,提高写性能
缺点:读请求,查询数据需要遍历全量数据,效率低,有重复冗余数据
如果对全量数据建索引,数据量大的时候,内存是装不下的,将索引放到磁盘中,存在和 B+ 树一样的问题
版本2:磁盘有序写
思路:直接写数据是无序的,如果数据是有序的,可以用二分查找提高读性能
写请求:用二分查找确定位置,插入 k-v 对,时间复杂度 O(logn)
读请求:二分查找,时间复杂度 O(logn)
优点:相比版本 1 提高了读性能
缺点:写数据有随机 IO,需要用链表维护有序关系,空间碎片化,利用率低
版本3:内存排序,磁盘追加写
思路:先写到内存的有序结构排序,写满了再顺序写到磁盘
写请求:先写到内存有序结构 M(可以是跳表或红黑树),写满了顺序写到磁盘,生成一个有序块 S,记录每个 S 的起始位置,清空 M;时间复杂度 O(logn)
读请求:先查内存 O(logn),再查磁盘,由于磁盘是部分有序,需要对所有 S 块从新到旧依次二分查找,时间复杂度 O(mlogn),m 是有序块个数
优点:相比版本 2 没有随机 IO,提高了写性能,磁盘空间连续,没有碎片,空间利用率高
缺点:1. 有重复冗余数据;2. 读放大;3. 内存写磁盘时无法再写入 4. 内存数据断电丢失
版本4:内存排序,异步追加写
思路:版本3 当内存 M 满了,在同步写到磁盘的期间,无法继续写入;可以新建一个 M',新数据写到 M',M 继续写磁盘
写请求:1. 冻结M,使 M 不可变,将 M 刷到磁盘;2. 创建 M',新数据写入 M'
读请求:按 M', M, Sn, Sn-1, ...,S0 的顺序查找
优点:在写磁盘期间也可以写新数据
缺点:1. 有重复冗余数据;2. 读放大;3. 内存数据可能断电丢失
版本5:对有序块 S 添加过滤器
思路:对于一个有序块 S,可以知道 S 的 key 范围 [kmin, kmax],但想知道 key 是否在 S 中,还需要二分搜索;如果提前知道 key 不在 S 中,可以减少搜索次数
写请求:在版本 4 基础上,对每个有序块 S 建立布隆过滤器
读请求:先判断 k 是否在 S 的 key 范围内,再过布隆过滤器,如果 k 不属于 S,跳过
优点:提高了对 S 的查询性能
缺点:同版本 4
版本6:对有序块合并
思路:随着有序块 S 的增多,读请求放大的倍数会越来越大,需要对 Sn, ..., S0 进行合并
具体怎么合并,直接看 LSM-Tree 的做法
LSM-Tree
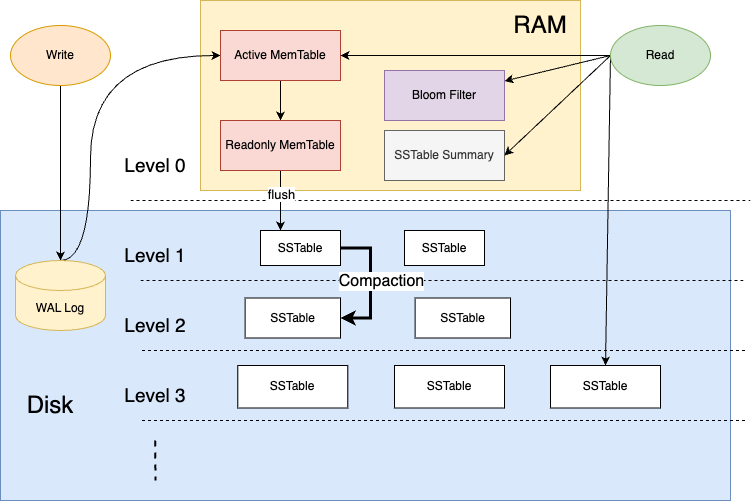
核心组件
MemTable
MemTable 是内存中的有序结构,可以用跳表或红黑树实现,对写到磁盘的数据预排序
写操作
- 如果 k 在 MemTable 中,覆盖已有的 k-v;如果 k 不在 Memtable,插入到 MemTable 中
- 删除操作,要对 k 加一个删除标记(不能直接删除,磁盘中还可能存在 k)
MemTable 中存的是对 key 的最新操作
读操作
- 如果 k 在 MemTable 中,没有删除标记,返回 k-v;如果有删除标记,返回空
- 如果 k 不在 MemTable 中,到磁盘中继续搜索
Flush
MemTable 达到一定大小,会把数据 Flush 到磁盘,生成一个有序的数据块(SSTable)
Flush 保证了磁盘的顺序写
为保证 Flush 过程中还可以继续写入 MemTable,先冻结当前 MemTable 为 readonly 状态,再 flush 到磁盘,同时创建一个新的 Active MemTable 接收写请求
Active MemTable:接收新的写入
Readonly MemTable:用来 Flush 到磁盘生成 SSTable
SSTable
SSTable(SST)是 Readonly MemTable flush 到磁盘生成的不可修改、内部有序的文件;基本结构如下:
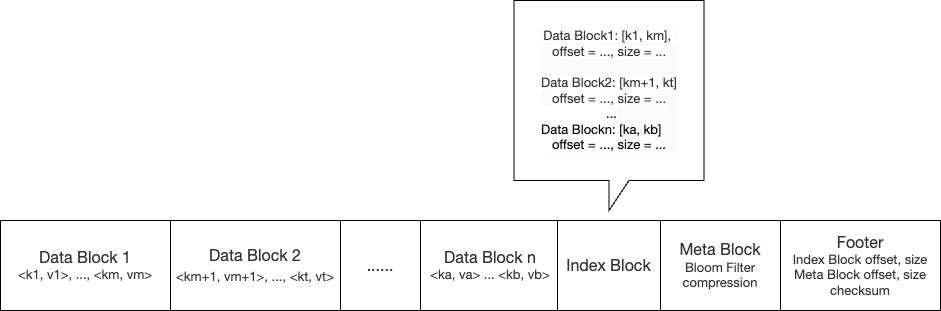
- 数据块(Data Block):存储若干个 k-v 对,按 key 顺序排列,每个数据块的大小通常是固定的,如 64KB
- 索引块(Index Block):快速定位某个 key 所在的数据块,每个索引条目包括数据块的起始 key,数据块在文件中的偏移量和大小
- 元数据块(Meta Block):存储布隆过滤器,压缩信息 等
- 文件尾部(Footer):存储 SSTable 的全局信息,包括索引块的偏移量和大小,元数据块的偏移量和大小,校验和 等
可以发现,在一个 SST 中查询 k 的时间复杂度是 O(n*m),n 是 Data Block 的个数,m 是一个 Data Block 中 k-v 对的个数;为保证查询效率,需要控制单个 SSTable 的大小
假设有 t 个 SST,由于 SST 之间是无序的,无法建立大小关系,只能从新到旧遍历所有 SST,时间复杂度是 O(n*m*t);随着 flush 次数的增多,对读性能有很大的影响,所以需要不定时合并 SSTable,控制 SSTable 数量
在合并两个 SST 时,如果两个 SST key 的范围没有交集,无法合并,如果有交集,按照归并排序进行合并(有相同的 key 取新的)
Level
SST 数量很多,什么时间对哪些 SST 合并呢?通过 Level 的设计来解决这个问题
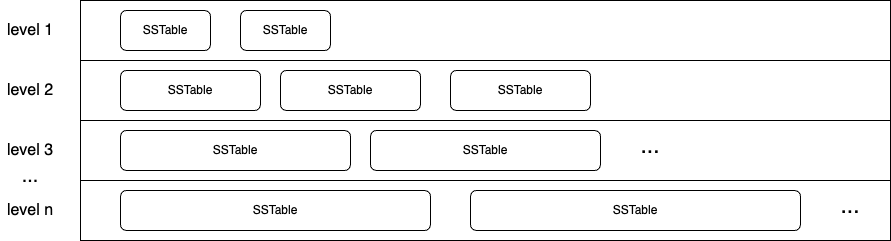
由于热数据访问频率高,冷数据访问频率低,将 SST 按产生时间分成不同层(从上到下 L1, ..., Ln),新的在上层,旧的在下层
每层规定如下:
- 每层 SST 数量和单个大小有限制,层数越大,SST 数量越多,单个体积越大
- MemTable Flush 到 L1 层,L1 层 SST 的 key 内部有序,整体无序,key 有重复
- L2 到 Ln 层,每层 SST 的 key 内部有序,整体有序,key 无重复
合并流程:
- 当 L1 数量超过限制时,发起合并:在 L1 中随机选择一个 SST_1,合并到 L2
- 如果 L2 中没有可以合并的 SST,直接将 SST_1 移动到 L2
- 如果在 L2 中找到可以合并的 SST(1个或多个),用多路归并进行合并,压缩成新的 SST_new
- 如果 SST_new 超过 L2 单个大小限制,拆成多个
- 如果 L2 SST 数量超过限制,重复上述流程,向下层合并,直到最后一层
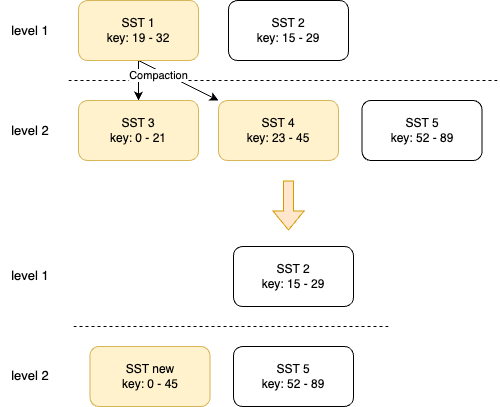
由于 level 2 至 level n 的 SST 都是上层合并产生的,可以保证同层的 key 没有重复且整体有序
一次合并可能引发多次合并
WAL Log
为防止 MemTable 的数据发生断电丢失,先写到一个日志文件 WAL Log 中,用来回放操作;
WAL Log 只需保存 MemTable 中的操作记录,每次清空 MemTable 后可以生成一个新的 WAL,flush 到磁盘后删除对应的日志文件
读写流程
了解完核心组件,看下一个完整的读写流程
写流程
Set k, v
- 写到 Active MemTable
- 如果 Active MemTable 已满,冻结为 Readonly MemTable,新建一个 Active MemTable
- Readonly MemTable Flush 到磁盘 L1,生成一个 SSTable
- 如果 L1 SSTable 数量达到限制,随机选择一个 SSTable 合并到 L2
- 如果 L2 也触发合并,依次类推到 Ln
读流程
get k, v
- 读 Active MemTable、Readonly MemTable
- 如果未找到 k,从新到旧的顺序依次读 L1 层的 SSTable
- 如果 k 在 SSTable 的 key 范围,且通过 Bloom Filter,在 SSTable 索引中查找所在的 Data Block,在 Data Block 中顺序查找
- 如果未找到 k,从左至右的顺序依次读 L2 层的 SSTable,直到 Ln 层
总结
本文介绍了 LSM-Tree 的设计思路,整体结构,核心组件
优点
- 将随机写转为顺序写,写入操作在内存中进行,延迟低,适合 高写入 的场景
- 分层结构和索引机制可以高效的处理海量数据
- 自动压缩机制,清理重复和过期数据,提高磁盘利用率
缺点
- 读放大:读取时可能需要检查多个 SSTable,导致读取性能下降
- 写放大:可能触发多次合并,是一个 IO 密集型操作,可能降低系统性能
- 内存命中率低:只有少部分数据在内存中,大部分读请求要访问磁盘,不适合读密集的场景
Reference
LSM Trees: the Go-To Data Structure for Databases, Search Engines, and More