本文介绍 redis RDB 持久化方式的原理
问题背景
Redis 作为内存数据库,数据存在掉电丢失的问题,虽然 Redis 中的数据一般是可以丢失的,不过如果由于故障关机,导致全部数据丢失,对系统也带来很大的风险。这时就需要把内存数据持久化到磁盘中,RDB 则是一个持久化的方式
方案设计
在介绍 RDB 原理前,先思考下如何将内存数据持久化到磁盘
方案1. 主进程中持久化
Redis 服务启动后,在操作系统中启动了一个进程,这个进程管理着 key - value,我们只需要遍历这些 k-v,然后写到文件中就可以了
方案 1 虽然实现了持久化的功能,但是在写文件的过程中,能否接受数据变更呢?如果有新的写操作进来,那我们最终得到的文件,就存在一些过期的数据,和实际内存中数据有一些 diff,关键是我们无法找到这些 diff,因为我们不知道数据是何时被写到文件的,也就不知道写入文件后又发生了什么;如果我们不允许有写操作,那么持久化过程中,服务将无法提供写服务,这个过程可能很长
为了解决上述问题,我们对方案1进行改进
方案2. 子进程中持久化
将主进程复制出一个子进程,通过子进程进行持久化,主进程继续向外提供读写服务,记录子进程创建的时间 t,持久化完成后就得到了 t 时刻的快照,对于 t 时刻持久化数据是完整和一致的
这里存在三个问题:
- 对父进程的写操作会不会影响子进程的数据
- 复制子进程占用多少内存
- 复制子进程需要花费多少时间
对于这些问题,下面介绍下 linux 的 fork 指令
fork
fork 系统调用 会为当前进程创建一个子进程,子进程拥有父进程的全部数据,父子进程数据隔离,父进程的修改不会影响子进程,子进程的修改也不会影响父进程
这样,子进程就像父进程fork时刻的快照,且在持久化过程中,不会因父进程的写入而改变数据
如果子进程将父进程的内存拷贝一份,对内存占用量很大,也会比较耗时,所以简单介绍下 fork 的 copyOnWrite 技术
Copy On Write
写时复制(COW):内核并不会立即复制整个地址空间,而是让父子进程共享地址空间,只有在某个进程试图修改共享内存时,才会复制一份专用副本给该进程
COW 的流程
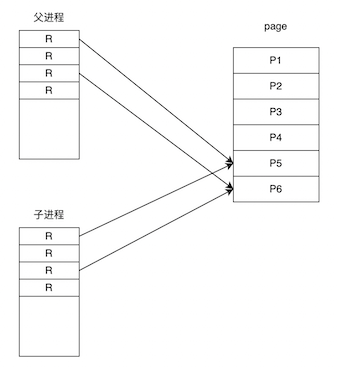
父子进程共享地址空间,都将PTE设置为只读 R
PTE的全称是Page Table Entry,它是一种数据结构,用于描述虚拟内存和物理内存之间的页面映射关系。PTE是页表(Page Table)中的一个条目,每个虚拟内存页面都对应一个PTE。PTE包含了一些字段,用于记录当前虚拟内存页面的状态和与之相关的物理内存地址
Page是内存管理中的单位,linux 中每个 page 大小是 4k
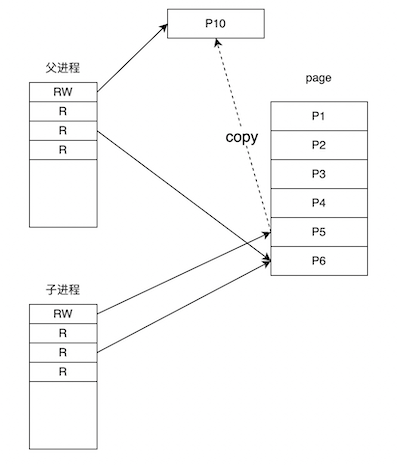
父进程执行 store 指令来更改 page P5 中的数据,由于 PTE 的状态是只读,会得到一个 page fault。得到 page fault 之后,我们需要分配一个 page P10,将 page fault 对应的 P5 拷贝到 P10 上,并将 P10 映射到父进程中,这时 P10 只对父进程可见,所以我们将父进程上 P10 对应的 PTE 状态改为可读写,然后父进程重新执行 store;现在 P5 只对子进程可见,所以讲 P5 在子进程上的 PTE 改为可读写
Page fault 页中断异常,触发条件:
- 当CPU访问某逻辑地址,而该地址还没有对应的页表项,即还没有分配相应的物理内存并进行映射
- CPU根据虚拟地址查询页表得到的结果是无效的
- 发生页访问权限错误,即CPU根据虚拟地址查询页表得到的结果是有效的,但是当前用户没有对该页的访问权限
COW 的优缺点分析
- 优点:减少分配和复制大量内存数据带来的空间消耗和操作时延
- 缺点:如果在 fork 后,父子进程还需要继续执行大量写操作时,会产生大量的 page-fault
所以,fork 出的子进程,不会受父进程写命令的影响,不会拷贝父进程 PTE 指向的内存,所以效率高,不会消耗大量内存