本文简述操作系统的虚拟内存
逻辑地址与物理地址
地址:用 1 字节将内存分成若干块,每一块头部的地址,称为内存的一个地址
逻辑地址:也叫虚拟地址,是程序看到的内存地址,是连续的
物理地址:实际的内存地址
32位操作系统物理地址有 2^32 个,因此最大内存为 2^32 byte = 2 ^ 22 KB = 2^12 MB = 2^2 G = 4G,大于4G的内存地址在32位操作系统中无法表示
任何一个32位程序的逻辑地址最多是2^32个
为什么要有逻辑地址
- 安全性:如果进程可以直接操作真实的内存地址,那可能两个进程同时修改同一个内存地址,导致系统崩溃
- 隔离性:不同进程之间的逻辑地址是不可见的,也就无法访问其他进程的数据
- 连续性:对程序而言,逻辑地址是连续的,方便进行地址计算
逻辑地址和物理地址的映射
映射思路
方法一:固定偏移量
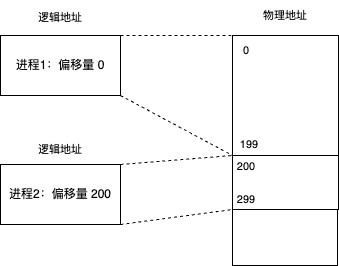
缺点:
- 进程分配的内存必须是连续的,如果分配到了另一个进程的内存空间,只能重新申请一份更大的连续空间,并将数据拷贝过去
- 产生很多内存碎片,内存利用率低
方法二:分页
固定偏移量法要求逻辑地址和对应的物理地址必须连续,这点很难实现,所以考虑将连续空间分解成若干小块,再进行对应
将逻辑内存分为多个页(Page),物理内存分为多个叶帧(Page Frame),通过页表(Page Table)映射,页表中每个条目是一个 Page Table Entry(PTE)
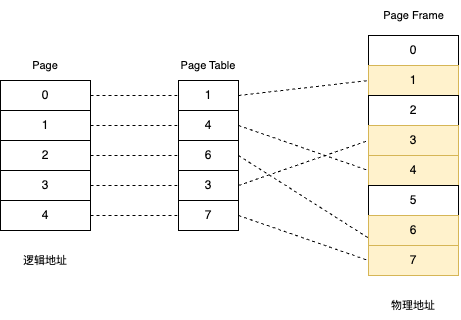
一个 Page 的大小:过大会产生碎片,过小要维护更多的映射关系。根据工业经验,Page 大小是 4KB
Page Table 如何完成地址映射?
现在我们有一个逻辑地址 x,想通过 Page Table(PT)查到对应的物理地址,PT 的数据结构可以是字典,key = 逻辑地址,通过散列算法进行映射,但是存在散列冲突和重平衡的问题;或者是一个线性表,长度为Page 的个数,由于 Page 大小固定,通过计算偏移量得到 Page 在线性表中对应的坐标,线性表一个单元存储物理地址,或者存物理地址 Page Frame 的偏移量,如果保存物理地址(最大值为 2^32-1)需要用 32 bit 存储;如果存储 Page Frame 的偏移量,则最大偏移量为 4G/4KB - 1 = 2^20 - 1,需要用 20 bit 来存储
所以选择存储偏移量,比存储物理地址占用的空间少,这样,物理地址的计算方法为: \[ \begin{align*} & PF_x = PT(P_x)*4*2^{10} + x\%(4*2^{10}) \end{align*} \] 其中,Px 为 x 所在 Page 的下标,PT(Px) 为 x 对应的物 PF 的下标,再转换为物理地址:即下标 * 一叶帧的大小得到 PF 的 head 地址,再加上 x 在 Page 中的偏移量:x%(4*2^10)
虽说如何,但是直接存储物理地址更快,所以目前都是直接存储物理地址
地址映射利用了逻辑地址的线性特征
问题1:一个进程的页表是一次性建好,还是进程申请内存多少,就创建多少呢?为什么
答:不确定
问题2:页表占用多少内存空间
思考:比如在32位操作系统中,一个进程的页表最多有220个,对应的页表最多有220个PTE,如果一次性创建长度为2^20的页表,为了方便计算,我们先设一个PTE大小为4Byte,则页表的总空间为 2^20 * 4B = 4MB需要4M的内存空间,当有很多进程同时运行时,是一个很大的开销
页面置换
由于逻辑内存是进程间隔离的,每个进程都认为自己有完整内存空间的逻辑内存,就存在物理内存不够用的情况,当物理内存不够用时,将不常用的内存页面交换到磁盘上,再把这些内存释放和分配给进程。在 Linux 系统中,可以通过 Swap 分区(Swap Partition)启用Page 与磁盘交互,Swap 分区是硬盘上的独立区域,只能用于交换分区,不能存储其他文件
常见的页面置换算法有:
- 先进先出(FIFO)页面置换算法:淘汰最先进入内存的页面
- 最不常用(Least Recently Used, LRU)页面置换算法:选择最长时间未被使用的页面予以淘汰
- 工作集(Working Set)页面置换算法:选择当前工作进程实际需要的页面予以保留,淘汰其他页面
Page Fault
Page Fault(缺页异常)是指当程序访问内存时,所访问的页面不在物理内存中,而是被交换到硬盘上。这时,操作系统会触发 trap 机制,进入内核状态,然后通过相应的处理函数将该页面重新加载到内存中,再返回到用户态,继续执行程序。缺页异常是一种实现虚拟内存的重要机制。
页表优化
虚拟内存扩展了可用内存,提高了内存使用的安全性,但增多了一步地址转换的步骤,影响了访问内存效率;同时页表自身也占用一定的内存,下面从时间和空间两个角度对页表进行优化
时间优化
TLB(Translation Lookaside Buffer)是内存中用于实现虚拟地址到物理地址映射的缓存,是MMU(Memory Management Unit)的一部分。TLB是一个高速缓存,它存储了当前最可能被访问到的页表项的一个副本,因此可以加快地址翻译的速度,提高处理器性能。当需要将虚拟地址翻译成物理地址时,MMU首先会在TLB中查找是否有匹配的条目,如果有,则称为TLB hit,直接使用TLB中保存的结果;否则,MMU需要访问页表,进行慢速的地址翻译,这会产生较大的开销
空间优化
上文说过,由于一级页表需要一次性加载完整的页表,对内存的占用很大,页表中很多PTE是空的,导致利用率很低;而一级页表的线性访问又不能将不用的PTE删除掉
二级页表
二级页表的思路:
有6个年级,每个年级5个班级,要记录这30个班级,在一级页表的场景中,是创建一个长度为30的表;不过老师们查看班级时基本都只关心本年级的班级,不需要完整的表,所以按照年级创建6个表,额外再创建一个表,表示班级要去哪个年级表中查看。这样,一位老师查看时,会返回一个只有5条记录的表
具体实现方式:
将虚拟地址的32位分为前10位、中间10位、最后12位
前10位作为一级页表(PGD)的索引映射到二级页表,中间10位作为二级页表(PTE)的索引映射到页帧的起始地址,最后12位是页内偏移
物理地址的寻址过程如下图
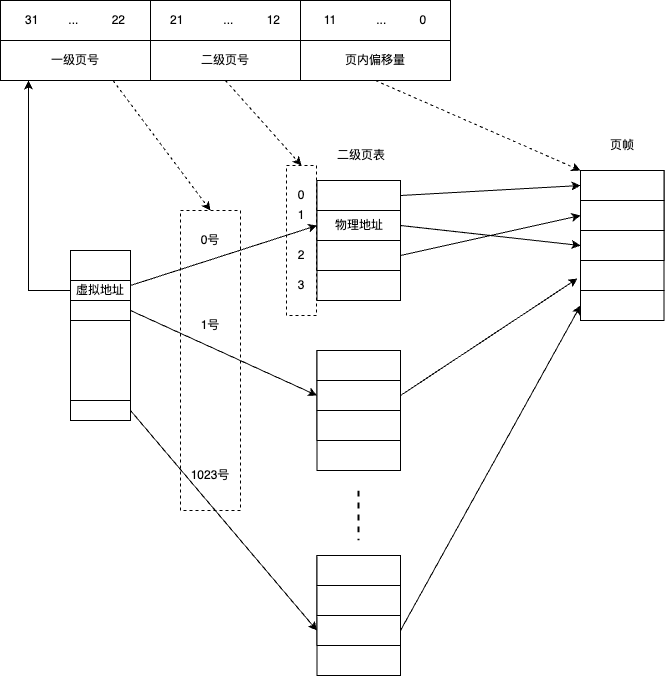
通过虚拟地址的高10位(可表示0 - 1023),定位到在哪个二级页表中,然后通过中间10位,在对应的二级页表中找到对应的页帧起始地址,最后通过低12位,计算页内偏移量,最后,物理地址 = 页帧起始地址 + 页内偏移量;这个寻址过程被称为 page table walk
这种方式看起来只是将之前的一级页面拆成了1024个二级页表,但总的空间没有减少,还加入了地址转换的逻辑,但1024个二级页表不需要同时加载到内存,需要加载一小部分二级页表,其余的页表持久化在磁盘,需要时再加载即可;假设我们最多允许1个二级页表在内存中,需要的内存计算如下:每个页表中有2^10个PTE,一个 PTE 为4B,需要内存 4KB,相比之前只有一级页表的 4M 节约了很大的内存空间(emmm...直接 4M/1024 更简单)
三级页表
当X86引入物理地址扩展(Pisycal Addrress Extension, PAE)后,可以支持大于4G的物理内存(36位),但虚拟地址依然是32位,原先的页表项不适用,页表项从 4Byte 被扩充到 8Byte,这意味着,每一页现在能存放的pte数目从1024变成512了。相应地,页表层级发生了变化,Linus新增加了一个层级,叫做页中间目录(page middle directory, PMD)
四级页表
64位操作系统中支持了48位的虚拟地址空间,将虚拟地址分为以下五个部分:
PGD:Page Global Directory(47-39),页全局目录 PUD:Page Upper Directory(38-30),页上级目录 PMD:Page Middle Directory(29-21),页中间目录 PTE:Page Table Entry(20-12),页表项 page offset: 偏移量
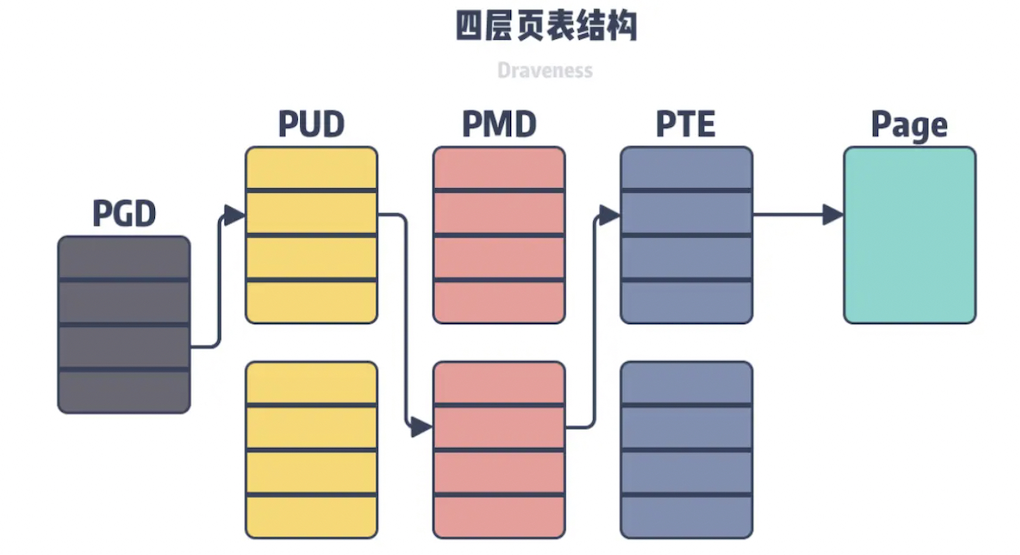
三级/四级页表产生的背景、原理还没有弄清楚,但思路和二级页表是一样的
局部性原理
上述的时间优化和空间优化,都是利用了局部性原理:
局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。具体可以分为时间局部性和空间局部性:
- 时间局部性:如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某数据被访问,则不久之后该数据可能再次被访问
- 空间局部性:是指一旦程序访问了某个存储单元,则不久之后,其附近的存储单元也将被访问