本文介绍 kafka 的延时消息
延时发送
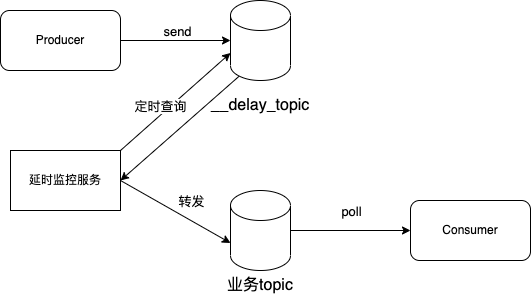 延时发送.drawio
延时发送.drawio
实现原理:
- 生产者发送到 __delay_topic
- 延时监控服务定时查询 __delay_topic,判断是否达到业务方设置的
delayTime 时间戳,达到了将消息转发到业务 topic
- 消费者消费业务 topic
这个方案对延时发送时间的准确性取决于监控服务的查询频率,假设延时发送为10s,查询频率是
5s 一次,则最大的误差为 4.999s,频率越高精度越高
这个方案存在的问题有:
- 占用更多磁盘空间:如果存在延时较长的消息,则需要延长所有消息的保存时间而无法清理,比如有延时10天和延时1小时的消息在一个__delay_topic中,只能保存10天以上
- 不够灵活:一般消息的延时时间是由下游业务确定的,而延时发送需要生产者来控制
上面问题的解决思路是,生产者将消息发送给消费者,由消费者控制延时时间,即延时消费
延时消费
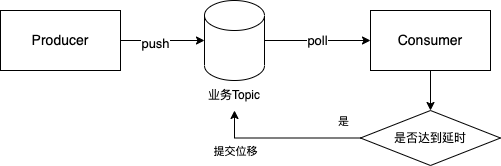 延时消费-单topic.drawio
延时消费-单topic.drawio
这个方案的好处是:
- 生产者不需要关心延时时间,完全交给消费者去处理,不同业务根据自身需要去设置延时时间和过期清理时间
- 生产者不再需要保存两份消息,且可自行设置合理的清理时间,缓解了生产者服务
kafka 集群压力
延时消费相比于延时发送,解决了生产者侧消息积压的问题,试想为了支持某个高延时的下游业务将清理时间调高,对集群的压力是非常大的,一旦崩溃会影响所有下游业务;同时,数据在生产者和消费者都只需要保存一份
下面讨论消费者服务如何控制延时消费
延时监控服务如何设计
延时发送中的延时监控服务,和延时消费的消费者,是相同的思路
方案一 定时轮训
消费者每次poll一个消息,如果达不到延时时间,则不提交位移,并 sleep
一段时间,实现周期性轮询
这个方案轮询的时间要小于max.poll.interval.ms,否则会发生
rebalance,存在问题:
- 资源浪费:大量无效轮训消耗系统资源
- 存在误差:假设设置轮训时间是
500ms,那么延时的最大误差就是499.999ms
方案二 根据剩余时间等待
消费者每次 poll
一个消息,如果达不到延时时间,则不提交位移,计算还需要等待的时间,sleep
这段时间后再 poll
这个方案避免了无效轮训,但是等待时间如何大于
max.poll.interval.ms,会导致 rebalance,所以不能使用 sleep
的方式等待
kafka consumer提供了暂停消费的API,暂停消费后 broker 不会认为
consumer 挂掉,等待剩余时间后恢复消费,再拉取消息
关于 max.poll.interval.ms 与
session.timeout.ms
max.poll.interval.ms :如果 poll 在
max.poll.interval.ms
内没有被调用,心跳线程会检测到这种情况并发起离组请求,即消费者主动离开;
session.timeout.ms :在 0.10.1 版本之前,消费者是通过 poll
请求与 broker 建立心跳,这样当消费处理时间较长时,就容易被 broker
误认为断连,0.10.1 之后将心跳与处理解耦,由心跳线程单独向 broker
发心跳包,如果心跳包间隔超过了 session.timeout.ms,则
broker 认为 consumer 断连
max.poll.interval.ms 触发的断连是消费者主动发起的,
session.timeout.ms触发的断连是消费者被动的
所以可不可以理解为,调用了 pause api,消费者心跳线程就不会因为 poll
间隔超过了 max.poll.interval.ms
而发出断连请求,下面进行代码演示
生产者代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| public class MyProducer {
private static final String TOPIC = "beihai";
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9093,127.0.0.1:9094,127.0.0.1:9092");
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.RETRIES_CONFIG, 0);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
for (int i = 1; i <= 10; i++) {
ProducerRecord<String, String> rec = new ProducerRecord<>(TOPIC, i % 2 == 0 ? 0 : 1, "key" + i,"message" + i);
RecordMetadata metadata = kafkaProducer.send(rec).get();
System.out.println("同步方式发送消息结果: " + "topic-" + metadata.topic() + "message-" + i + " partition-" +
metadata.partition() + " offset-" + metadata.offset() + "time: " + CommonUtils.formatTime(new Date()));
Thread.sleep(10000);
}
kafkaProducer.close();
}
}
|
消费者代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| public class ConsumerFactory {
public void startDelayConsumer(String topic, String consumerGroup, String clientId, Long delayMills) throws InterruptedException {
delayRun(topic, consumerGroup, delayMills, clientId);
}
private void delayRun(String topic, String consumerGroup, Long delayMills, String clientId) throws InterruptedException {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9093,127.0.0.1:9094,127.0.0.1:9092");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 1);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 5000);
properties.put(ConsumerConfig.CLIENT_ID_CONFIG, clientId);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, consumerGroup);
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
List<String> TOPIC_LIST = Collections.singletonList(topic);
kafkaConsumer.subscribe(TOPIC_LIST);
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> record : consumerRecords) {
TopicPartition topicPartition = new TopicPartition(topic, record.partition());
Long now = new Date().getTime();
Long alreadyDelayTime = now - record.timestamp();
Long leftDelayTime = delayMills - alreadyDelayTime;
if (alreadyDelayTime < delayMills) {
kafkaConsumer.pause(Collections.singletonList(topicPartition));
kafkaConsumer.seek(topicPartition, record.offset());
Thread.sleep(leftDelayTime);
kafkaConsumer.resume(Collections.singletonList(topicPartition));
} else {
handle(record);
kafkaConsumer.commitSync();
}
}
}
}
private static Integer handle(ConsumerRecord<String, String> record) {
System.out.printf("handle record: partition %s - message %s - sendTime %s - receiptTime %s - delayTime %s\n",
record.partition(), record.value(),
CommonUtils.formatTime(record.timestamp()),
CommonUtils.formatTime(new Date()), new Date().getTime() - record.timestamp());
return 1;
}
}
|
运行结果如下
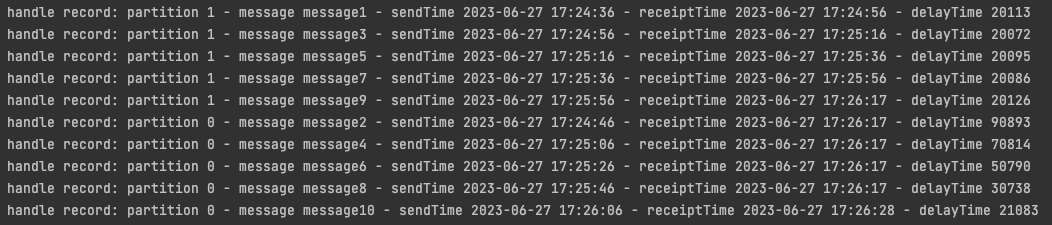 image-20230627172859178
image-20230627172859178
可以看到,在分区1中的消息,接收时间 = 发送时间 +
20s,但是分区0中的消息,延时超过了20s
这是因为代码中 resume
到了固定的分区,导致无法切换分区;即使手动resume到其他分区,也无法同时对多个分区延时消费,这是因为在一个分区内是有序的,但是分区之间是无序的,单线程在当前分区等待时,其他分区的消息可能已经过时了,所以需要用多线程的方式。
Reference
Kafka
延时队列,重试队列,死信队列
Kafka--延迟队列--使用/实现/原理
Kafka 的
session.timeout.ms 和 max.poll.interval.ms 之间的差异 >=
0.10.1
springboot
kafka 实现延时队列
kafka
commit机制以及问题