本文介绍 kafka 相关运行机制,主要包括:
- 分区策略
- 消息压缩算法
- Kafka 通信方式
- 消费者组相关机制
分区策略
kafka的分区机制提供了负载均衡的能力,实现了系统的可伸缩性
我们希望生产者将消息均匀的分发到每个分区中,分区策略有:
- 轮询策略
- 随机策略
- 按消息键保序策略
消息压缩算法
希望以极小的CPU开销带来更少的磁盘占用或更少的网络I/O传输
Q1:什么时候进行压缩?
A1:生产者 或 Broker
Broker 压缩的情况:
- Producer压缩消息后,发送到Broker,如果Broker指定了压缩算法,且与Producer的算法不同,则会解压后重新压缩;
- Broker 端发生了消息格式的转换,比如 Broker 发现有旧版本的消息,需要解压转换为新版本格式,再压缩
Broker 压缩会影响性能,应该尽量避免由于压缩算法设置不一致,或消息版本不一致导致的重复压缩
Q2:什么时候进行解压?
A2:Broker 或 消费者
除了上面提到的 Broker 压缩前需要解压外,每个压缩过的消息在 Broker 端都会解压,对消息执行各种校验;
Think:Broker 具体校验哪些方面呢,能否可以在不解压的情况下校验呢?
有哪些压缩算法?
- GZIP
- Snappy
- LZ4
- Zstandard(zstd)
四种压缩算法的比较:
- 压缩比:zstd > lz4 > gzip > snappy
- 吞吐量:lz4 > snappy > zstd 和 gzip
即:如果希望节省网络带宽,则使用 zstd;如果追求速度,则使用lz4
如何防止 kafka 消息丢失
可能导致消息丢失的场景:
- 生产者端丢失:发送过程中由于网络问题、消息不合格等原因,且生产者未感知
- 消费者端丢失:先更新offset,后消费消息,如果更新offset后消费消息的线程中断,则它负责的消息没有处理,但是 offset 却更新了
对于上述两种场景的解决方案是:
- 生产者端:使用带有回调的 send 方法,在回调中发现失败进行重试等处理
- 消费者端:先消费,成功后再提交更新 offset
防止消息丢失的最佳实践:
- 【生产者端】使用 producer.send(msg, callback)
- 【生产者端】设置 acks = all,表示全部 broker 都收到消息,才认为是已提交
- 【生产者端】设置 retries 为一个较大值,自动重试消息发送
- 【Broker端】unclean.leader.election.enable = false,不允许一个落后原先 leader 太多的 broker 成为新的 leader
- 【Broker端】设置 replication.factor >= 3,将消息多保存几份
- 【Broker端】设置 min.insync.replicas > 1 消息至少要被写入多少个副本才算是已提交
- 【Broker端】确保 replication.factor > min.insync.replicas,推荐 replication.factor = min.insync.replicas + 1
- 【消费者端】消费成功后再提交
Kafka 的通信方式
生产者是如何和Broker通信的
通信协议:TCP
什么时候建立连接:
- 创建 producer 实例时,生产者应用会在后台创建一个线程,该线程会与 bootstrap.server 参数中指定的所有 Broker 创建连接
- Producer 与 bootstrap.server 的 Broker 请求 kafka 集群 Metadata,拿到集群的全部 Broker 后,Producer 会与未建立连接的 Broker 建议连接,这样 Producer 就与集群中所有 Broker 都建立了连接
- Producer 在发送消息时,如果发现与目标 Broker 未建立连接,会创建连接
消费者组
消费者组的作用
使消费者的水平扩展,提高消费能力
位移是如何管理的
不同的版本位移的管理是不同的
2.8.0 之前:zookeeper
2.8.0 之后:kafka 内部主题 __consumer_offsets
位置放在 zookeeper 中存在的问题:zookeeper 不适合频繁的写更新,大吞吐量的写操作会极大地拖慢 zooKeeper 集群的性能
位移主题:保存消费者的位移信息,需要保证持久性和高吞吐量
consumer 如何提交位移:
自动提交
参数:
enable.auto.commit = true
auto.commit.interval.ms = 5000
执行流程:周期性的 poll(拉取)消息前,都提交上次 poll 的位移
优缺点:可以保证消息不丢失,但可能重复消费
为什么会重复消费:在一个周期内发生重平衡,重平衡后再开始消费,由于本周期的位移没有提交,拿到的位移是本周期前的,导致重平衡前本周期消费的消息被重复消费
手动-同步提交
kafkaConsumer#commitSync()
优缺点:灵活可控,提交失败可以自动重试,但提交过程中会阻塞消费者进程,也有重复消费的问题(已消费未提交位移时重启、重平衡)
手动-异步提交
kafkaConsumer#commitAsync()
优缺点:灵活,异步提交,不阻塞消费进程,缺点是发现提交失败,也无法重试,因为重试提交的也不是最新的位移,只会导致重复消费
综上,无论用哪种提交位移的方式,都会产生重复消费,所以需要消费者自己处理重复消费,如天然是幂等的,或去重
消费者重平衡
何时发生重平衡:
- 消费者组成员数量发生变更
- 订阅主题数发生变更
- 订阅主题的分区数发生变更
重平衡的影响:在重平衡过程中,组内所有实例都不能消费任何消息,影响了消费者的 TPS
消费者线程
从 0.10.1.0 版本开始,kafka consumer 采用了用户主线程和心跳线程的双线程设计,是为了将心跳线程与主线程的 poll 方法分开,防止因消费时间过长无法及时 poll 导致的重平衡
在单节点上,消费线程是单线程。如果希望多线程消费,可以采用下面几种方案:
- 方案一:启动多个消费者线程,即拉取消息又处理消息
- 方案二:单(多)消费者线程负责拉取消息,多线程处理
方案一就是在一个节点上启动了多个消费者,和启动多个消费者节点是一样的,所以启动的消费者数受限于主题分区数,如果启动了大于分区数的消费者,那么多启动的线程也是空闲的
方案二将拉取消息与处理消息分开,如果拉取消息是多线程,与方案一相同,多线程处理消息可以提高消费速度,但是不能保证消息有序消费;多线程消费需要手动提交位移,需要感知到当前 poll 的消息全部处理完
位移管理
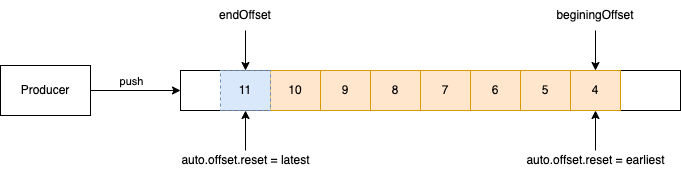
消费者接入到一个 partition 后从哪个位置开始消费,与
auto.offset.reset 有关:
- earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
- latest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
- nearlist: 当各分区下有已提交的offset时,从提交的offset开始消费;如果小于 beginingOffset 从 earliest 开始,如果超过 endOffset 从 latest 开始
消费者负载不均衡
消费模式
顺序消费
通过分配规则,对消息 key 计算出对应的 partition,发送到指定的 partition 中
Q:什么情况会破坏顺序消费?
A:批量消费,没有去重,发生 Rebalance 时,可能破坏顺序
比如批量 poll 了一批消息 [a1, a2, a3, a4, a5],已经消费到 a4,还没有提交位移,这时发生了 rebalance,则 rebalance 后会重新消费 a1, a2, a3, a4(不去重的情况),这时发生了先消费 a3,后消费 a1 的情况
延时消费
见延时消费
集群设置
broker 负载均衡
consumer 负载均衡
负载均衡策略(Rebalance 策略)
Range 算法
- 对每个 topic 里面的分区按序号排序(P0, P1, P2,...),对消费者按字母顺序排序(C0, C1, C2, ...)
- 对每个 topic 都执行操作:将分片依次分配给消费者
存在的问题:多个 topic,且分区大于消费者个数时,排序靠前的消费者会分配到更多的分区,比如有 N 个 topic,每个 topic 的分区数都比消费者个数多一个,则 C0 比其他消费者多分配 N 个分区
RoundRobin 算法
- 遍历主题列表,从每个主题获取其所有分区的列表,组成分区集合 P
- 对 P 中分区列表进行排序,首先按照主题名称,然后按照分区编号进行排序
- 对消费者实例进行排序,保证分配过程中的顺序是确定的
- 系统遍历P中的分区列表,从第一个消费者开始,依次分配一个分区,直至分配完列表中的所有分区
存在问题:
Sticky 算法
目标:
- 分区的分配要尽可能的均匀,分配给消费者者的主题分区数最多相差一个
- 分区的分配尽可能的与上次分配的保持相同
步骤:
- 按照 RoundRobin 的方式分配
- 发生重平衡时,将离线消费者的分区分配给在线消费者,保证分区差不超过1个
消费者组不均衡的场景
- 场景1:消费者组订阅了多个topic,而 topic 之间流量差异很大,默认的分配策略是不考虑 topic 具体流量的,只会按分区数分配
- 场景2:有一些内置 topic,如 RETRY_TOPIC,这些内置 topic 平时流量很少,但也参与分配;这就可能导致一些实例上的消费者只分配了内置 topic 的分区,而一些实例上分配了正常 topic 的分区,导致负载不均(与场景1其实是同一个问题)
解决方案:
- 场景1:给不同 topic 设置权重,按照权重分配
- 场景2:给内置 topic 设置权重为0
服务实例分配分区不均衡的场景
由于分区分配策略是在消费者组内部的,不会考虑其他消费者组已分配的分区,当服务实例在多个消费者组中,容易出现不均衡的现象,下面是可能发生的场景:
场景1:使用 RoundRobin 策略,3个实例(A,B,C),在2个消费组内,订阅2个Topic,各4个分区(P0-0, P0-1, P0-2, P0-3, P1-1, P1-2, P1-3, P1-4)
分配后的结果为:A分配了P0-0,P0-3,P1-1, P1-4, B分配了P0-1,P1-2,C分配了P0-2,P1-3,可以发现A比B,C多分配了两个分区,如果在更多的消费组中,则这个问题会更严重
场景2:使用 Sticky 策略,3个实例(A,B,C)同上
先看一个消费组内,在启动服务的过程中,由于分配策略和服务启动先后有关,则一定有一个实例多分配了一个,在N个消费组的情况下,这个实例会被多分配N个分区(因为不同消费组的分配策略是一致的)
场景3:使用任何一种策略,10个实例,在30个消费者组中,30个topic,每个topic4个分区
分配后,肯定存在4个实例,被分配了30个分区,6个实例,分配0个分区
实验验证
只验证场景1,2,场景3同理
3个Topic,每个 topic 4个分区,3个消费者组,每组3个消费者,client.id 依次是 c1, c2, c3
使用 RoundRobin 和 Sticky 策略,观察分区分配的结果
RoundRobin策略
| 分配结果 | 分区统计 | |
|---|---|---|
| 第一个消费者上线 | 所有分区都是C1 | C1:12个 |
| 第二个消费者上线 | T0-P0,P2:C1 T0-P1,P3:C2 T1-P0,P2:C1 T1-P1,P3:C2 T2-P0,P2:C1 T2-P1,P3:C2 |
C1:6个 C2:6个 |
| 第三个消费者上线 | T0-P0,P3:C1 T0-P1:C2 T0-P2:C3 T1-P0,P3:C1 T1-P1:C2 T1-P2:C3 T2-P0,P3:C1 T2-P1:C2 T2-P2:C3 |
C1:6个 C2:3个 C3:3个 |
Sticky 策略
| 分配结果 | 分区统计 | |
|---|---|---|
| 第一个消费者上线 | 所有分区都是C1 | C1:12个 |
| 第二个消费者上线 | T0-P0,P1:C1 T0-P2,P3:C2 T1-P0,P1:C1 T1-P2,P3:C2 T2-P0,P1:C1 T2-P2,P3:C2 |
C1:6个 C2:6个 |
| 第三个消费者上线 | T0-P0,P1:C1 T0-P2:C2 T0-P3:C3 T1-P0,P1:C1 T1-P2:C2 T1-P3:C3 T2-P0,P1:C1 T2-P2:C2 T2-P3:C3 |
C1:6个 C2:3个 C3:3个 |
可以发现,在RoundRobin策略和Sticky策略中,C1比C2,C3多分配3个分区
解决方案
上面两个场景的本质是相同的,都是多消费者组分配分区执行结果一致,导致部分实例被多分配
场景1:不同消费组对消费者排序后,机器的顺序是相同的,排序的算法对 client.id 的 hashCode 进行排序的,所以只要让同一实例上不同组内的消费者 client.id 不同,就可以避免这个问题
场景2:Sticky分配策略与启动顺序有关,且消费者进程和服务启动是同步的,解决方案是将消费者进程的启动和实例的启动解耦,通过随机睡眠的方式,利用消费者进程启动的随机性,避免这个问题
场景3:无论使用哪种策略,都要加入随机睡眠
Reference
如何为Kafka集群选择合适的Topics/Partitions数量