本文简述 Java 注解原理
你可以收获:
- Java 文件的编译过程
- 插入式注解的原理
- 什么是抽象语法树
- 如何自己实现一个 lombok
- 运行时注解的原理
注解的分类
根据注解的生命周期,可以分为三类:
- SOURCE:编译器可见,不会写入 class 文件
- CLASS:会写入 class 文件,在类加载阶段丢弃
- RUNTIME:会加载到 JVM
根据注解的操作形式,可以分为两类:
- 插入式注解:插入式注解(也叫编译时注解)内容只存在源文件,在编译期间被丢弃,不能通过JVM获取注解信息,Retention=SOURCE
或 CLASS
- 运行时注解:编译时被写入字节码文件中,可以通过 JVM
运行时获取注解信息(Retention=RUNTIME)
注解的作用与好处
作用:
- 生成文档:如 @authr
@version
- 标注说明:如 @Override @Deprecated
- 实现能力:如 lombok、AspectJ 框架 以注解方式提供功能
好处:
- 减少手动实现冗余代码,使代码简洁,如 lombok、BufferKnife 等
- 对业务代码低侵入,如 BTrace 追踪工具
编译过程
在介绍插入式注解,需要先了解 java 的编译过程
编译:将便于人编写、阅读、维护的高级计算机语言写的源代码程序,翻译为计算机能解读、运行的低阶机器语言的程序的过程。负责这一过程的处理的工具叫做编译器
简单理解,编译 = 高级语言源代码 → 分析 + 翻译 + 优化
→ 低级语言机器码
源码编译流程如图所示:
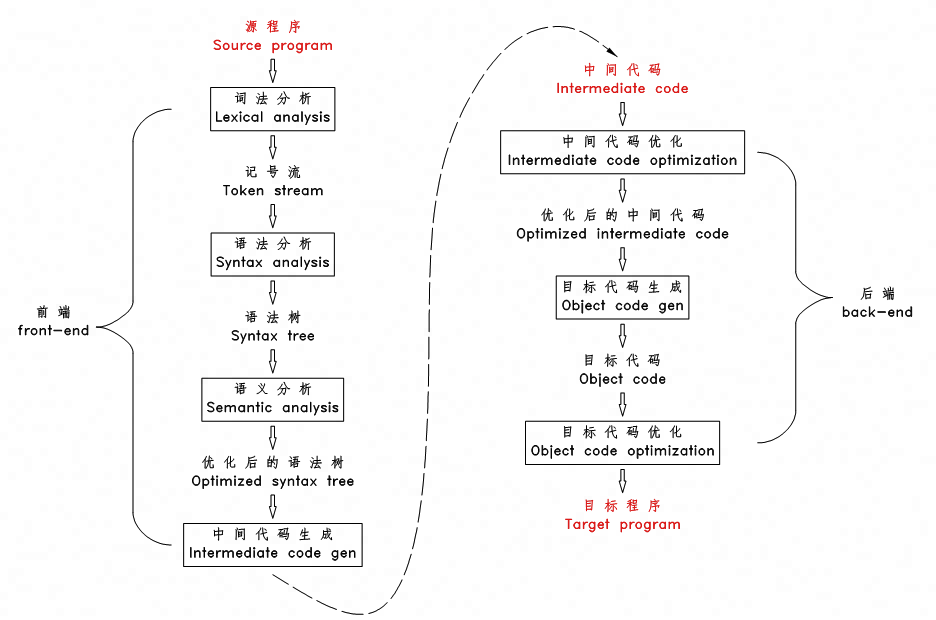 image-20230326135858492
image-20230326135858492
其中【中间代码】指的就是字节码(.class文件),字节码无法被机器识别,还需要
JVM 再将字节码转为机器码
编译阶段的编译器和对应任务如下:
| 前端编译器 |
.java → .class |
javac |
| 后端编译器 |
.class → 机器码 |
HotSpot 的 C1、C2 编译器 |
Ref:https://rensifei.site/2017/03/javac/
前端编译
大致可以分为3个过程:
- 解析与填充符号表(Parse and Enter)
- 注解处理(Annotation Processing)
- 语义分析与字节码生成(Analyse and Generate)
 编译阶段.drawio
编译阶段.drawio
Parse and Enter
该阶段将源码解析构建抽象语法树(Abstract Syntax
Tree,AST)。从功能上分为词法分析和语法分析
| 词法分析 |
源代码字符流 |
标记(Token)集合 |
关键字、变量名、字面量、运算符 |
将Java源代码按照Java关键字、自定义关键字、符号等按顺序分解为了可识别的Token流 |
| 语法分析 |
标记(Token)集合 |
抽象语法树(AST) |
包、类型、运算符、修饰符、接口、返回值、代码注释 |
将Token流组装成更结构化的语法树,描述程序代码语法结构,检查是否符合Java语言规范 |
| 填充符号表 |
|
符号表(Symbol Table) |
|
由 com.sun.tools.javac.comp.Enter
按照递归向下的顺序解析语法树,将所有类中出现的符号输入到自身的符号表,并将这些符号都存储到一个To
do List中。将这个To do List中的所有类都解析到各自的符号列表中(@-@不懂) |
Annotation Processing
插入式注解处理器的处理过程,通过操作语法树,实现功能,具体的在后面讨论
Analyse and Generate
| 语义分析 |
抽象语法树 |
标注检查和数据流分析后的语法树 |
进行标注检查(变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配),数据及控制流分析(局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理) |
| 解语法糖 |
泛型、变长参数、自动装箱/拆箱、断言等 |
还原回简单的基础语法结构 |
语法糖对语言的功能没有任何影响,只是更方便使用,让程序更简洁和可读性。JVM运行时不支持这些语法糖语法,需要在编译阶段还原回简单的基础语法结构,这个过程称为解语法糖 |
| 字节码生成 |
抽象语法树、符号表 |
字节码文件 |
前面各个步骤所生成的信息(语法树、符号表)转化成字节码写到磁盘中 |
Ref: 浅析java中的语法糖
后端编译
目前 JVM 采用解释器和 JIT(Just-In-Time Compiler)混和模式
没有 JIT 的情况下,javac 将源码编译为字节码,JVM
解释器逐条读入字节码,逐条解释,翻译成对应的机器指令。经过解释,执行速度必然比可执行的二进制码程序执行慢;为了提高执行速度,引入了
JIT。JIT 会把热点代码(Hot Spot
Code)翻译过的机器码保存起来,已备下次使用
所以 Java 是解释型还是编译型语言呢?
答:前端阶段属于编译,后端阶段属于解释 + 编译的混合模式
插入式注解
插入式注解(也叫编译时注解)内容只存在源文件,在编译期间被丢弃,不能通过JVM获取注解信息,Retention=SOURCE
或 CLASS
原理
由上面介绍的Java源码编译过程可知,插入式注解,是处于前端编译的Annotation
Processing步骤,通过操作抽象语法树(AST)实现对应的方法
认识抽象语法树
使用 JDT AST 插件,对下面的代码生成语法树
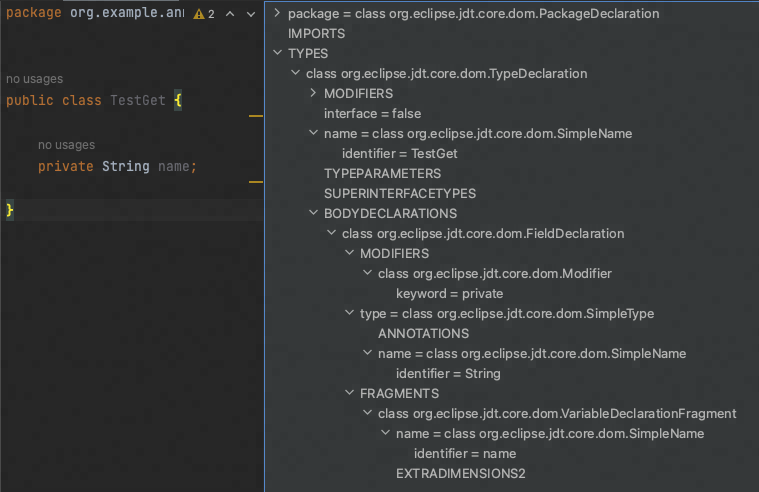 image-20230326204009345
image-20230326204009345
新增了 getName 方法,重新生成语法树,查看区别
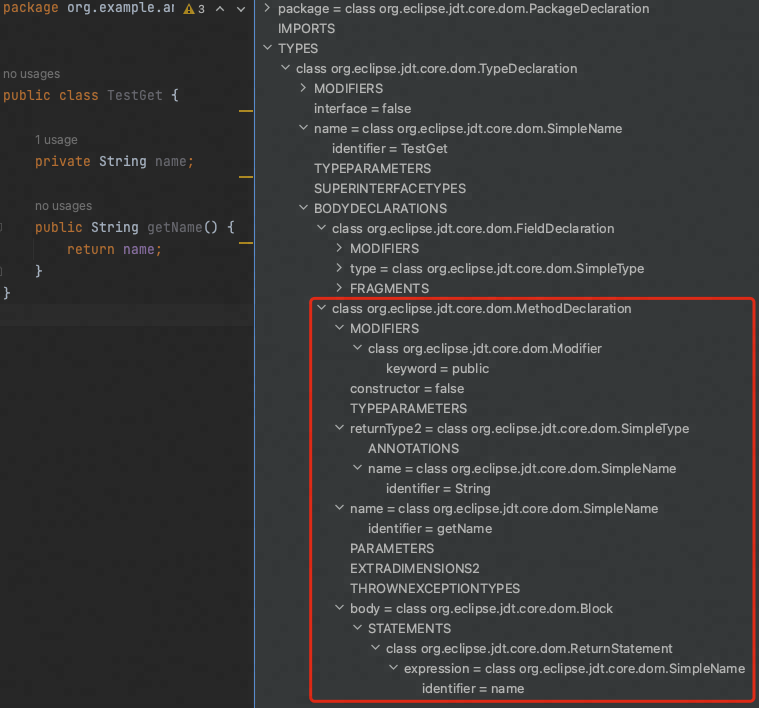 image-20230326204126350
image-20230326204126350
所以操作语法树,创建 MethodDeclaration
节点,就相当于新增了一个方法
下面介绍如何操作语法树
操作抽象语法树
JCTree
JCTree 是语法树元素的基类,JCTree 的一个子类就是 java
语法中的一个节点,类、方法、字段等这些都被封装成了一个JCTree子类
JCTree
包含一个重要的字段pos,该字段用于指明当前节点在语法树中的位置,不能直接用new关键字来创建语法树节点,因为不指明
pos 的节点是没有意义的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| @Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
Set<? extends Element> elementSet = roundEnv.getElementsAnnotatedWith(Getter.class);
elementSet.forEach(element -> {
JCTree jcTree = trees.getTree(element);
jcTree.accept(new TreeTranslator() {
@Override
public void visitClassDef(JCTree.JCClassDecl jcClassDecl) {
for (JCTree tree : jcClassDecl.defs) {
if (tree.getKind().equals(Tree.Kind.VARIABLE)) {
JCTree.JCVariableDecl variable = (JCTree.JCVariableDecl) tree;
System.out.println("variable " + variable.getName() + "\t pos " + variable.getPreferredPosition());
}
if (tree.getKind().equals(Tree.Kind.METHOD)) {
JCTree.JCMethodDecl method = (JCTree.JCMethodDecl) tree;
System.out.println("method " + method.getName() + "\t pos " + method.getPreferredPosition());
}
}
super.visitClassDef(jcClassDecl);
}
});
});
return false;
}
variable name pos 74
variable age pos 101
variable color pos 126
method <init> pos 145
method say pos 213
method jump pos 284
method toString pos 333
|
上面的例子可以看到,通过遍历 JCTree
可以得到类的属性、方法节点,JCTree 的子类的含义如下:
 image-20230329001730499
image-20230329001730499
JCTree 利用访问者模式,来操作 JCTree
节点,目的是将数据与数据的处理进行解耦
简单说下访问者模式:数据与数据的处理进行解耦
现有数据是鸡🐔,对鸡的处理有很多:老张想养做宠物,小春想用来下蛋,小红想做宫保鸡丁,小王想咖喱鸡块,坤坤想...(很多很多人,对鸡的处理都不一样),这样在实现时,需要写很多的
if 判断。用访问者模式,可以让鸡提供一个 accept(Vistor)
方法,不同的人是不同的 Visitor,具体的处理是 Visior.visit(鸡)
方法,当老张来处理,则 鸡.accept(老张),accept 里会调用
老张.visit(this),然后执行老张的处理逻辑
具体见:访问者模式
Ref:java
AbstractProcessor 编译时注解(API)
TreeMaker
TreeMaker 用于创建一系列的语法树节点,上面说了创建 JCTree
不能直接使用 new 关键字来创建,所以 Java 为我们提供了一个工具,就是
TreeMaker,必须使用上下文相关的TreeMaker对象来创建语法树节点,它在创建时为我们创建的
JCTree 对象设置 pos 字段
TreeMaker 常用方法见下面链接
Ref:Java
中的屠龙之术:如何修改语法树?
注解处理器
注解处理器(Annotation Processing
Tool,简称APT),是JDK提供的工具,用于在编译阶段未生成class之前对源码中的注解进行扫描和处理
处理方式对注解修饰的类的 AST 进行修改,生成新的 AST
实例演示
Demo1. Javac 编译版
下面通过开发注解处理器,给一个类自动生成 Getter 方法,实现类似 lombok
的效果
首先声明一个注解类,生命周期在 SOURCE 或 CLASS 都可以
1
2
3
4
5
| @Target({ElementType.TYPE})
@Retention(RetentionPolicy.SOURCE)
public @interface Getter {
}
|
编写Getter注解处理器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
| import com.sun.source.tree.Tree;
import com.sun.tools.javac.api.JavacTrees;
import com.sun.tools.javac.code.Flags;
import com.sun.tools.javac.processing.JavacProcessingEnvironment;
import com.sun.tools.javac.tree.JCTree;
import com.sun.tools.javac.tree.TreeMaker;
import com.sun.tools.javac.tree.TreeTranslator;
import com.sun.tools.javac.util.Context;
import com.sun.tools.javac.util.List;
import com.sun.tools.javac.util.ListBuffer;
import com.sun.tools.javac.util.Name;
import com.sun.tools.javac.util.Names;
import javax.annotation.processing.AbstractProcessor;
import javax.annotation.processing.Messager;
import javax.annotation.processing.ProcessingEnvironment;
import javax.annotation.processing.RoundEnvironment;
import javax.annotation.processing.SupportedAnnotationTypes;
import javax.annotation.processing.SupportedSourceVersion;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.Element;
import javax.lang.model.element.TypeElement;
import javax.tools.Diagnostic;
import java.util.Set;
@SupportedAnnotationTypes("org.example.anno.Getter")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class GetterProcessor extends AbstractProcessor {
private Messager messager;
private JavacTrees trees;
private TreeMaker treeMaker;
private Names names;
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
this.messager = processingEnv.getMessager();
this.trees = JavacTrees.instance(processingEnv);
Context context = ((JavacProcessingEnvironment)processingEnv).getContext();
this.treeMaker = TreeMaker.instance(context);
this.names = Names.instance(context);
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
Set<? extends Element> set = roundEnv.getElementsAnnotatedWith(Getter.class);
set.forEach(element -> {
JCTree jcTree = trees.getTree(element);
jcTree.accept(new TreeTranslator() {
@Override
public void visitClassDef(JCTree.JCClassDecl jcClassDecl) {
List<JCTree.JCVariableDecl> jcVariableDeclList = List.nil();
for (JCTree tree : jcClassDecl.defs) {
if (tree.getKind().equals(Tree.Kind.VARIABLE)) {
JCTree.JCVariableDecl jcVariableDecl = (JCTree.JCVariableDecl) tree;
jcVariableDeclList = jcVariableDeclList.append(jcVariableDecl);
}
}
jcVariableDeclList.forEach(jcVariableDecl -> {
messager.printMessage(Diagnostic.Kind.NOTE, jcVariableDecl.getName() + " has been processed");
jcClassDecl.defs = jcClassDecl.defs.prepend(makeGetterMethodDecl(jcVariableDecl));
});
super.visitClassDef(jcClassDecl);
}
});
});
return false;
}
private JCTree.JCMethodDecl makeGetterMethodDecl(JCTree.JCVariableDecl jcVariableDecl) {
ListBuffer<JCTree.JCStatement> statements = new ListBuffer<>();
statements.append(treeMaker.Return(treeMaker.Select(treeMaker.Ident(names.fromString("this")), jcVariableDecl.getName())));
JCTree.JCBlock body = treeMaker.Block(0, statements.toList());
return treeMaker.MethodDef(treeMaker.Modifiers(Flags.PUBLIC), getNewMethodName(jcVariableDecl.getName()), jcVariableDecl.vartype, List.nil(), List.nil(), List.nil(), body, null);
}
private Name getNewMethodName(Name name) {
String s = name.toString();
return names.fromString("get" + s.substring(0, 1).toUpperCase() + s.substring(1, name.length()));
}
}
|
Ref:Lombok原理分析与功能实现
要生成 Getter 方法的类
1
2
3
4
5
6
| @Getter
public class Dog {
private String name;
}
|
编译 Dog.java,指定注解处理器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class Run {
public static String commonPath = "/Users/zhangjiaming/workspace/gitlab/java-agent-demo/anno-demo";
public static void main(String[] args) {
String str = commonPath + "/src/main/java/org/example/anno/Dog.java";
com.sun.tools.javac.main.Main compiler = new com.sun.tools.javac.main.Main("javac");
args = new String[] {
"-processor", "org.example.anno.GetterProcessor",
"-processorpath", commonPath + "/src/main/java",
"-d", commonPath + "/classes",
str
};
int rc = compiler.compile(args).exitCode;
System.out.println("result code : " + rc);
}
}
|
运行后,查看Dog.class的反编译结果,发现已生成 getName 方法
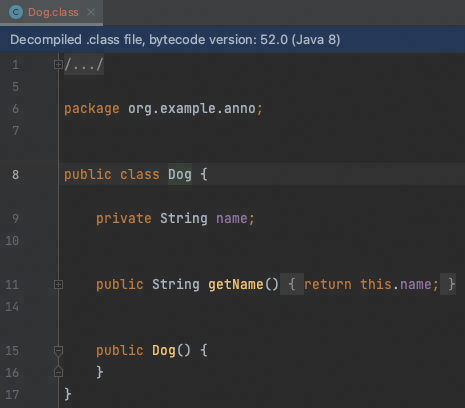 image-20230328142409017
image-20230328142409017
Demo.2 mvn打包版
注解工程
上面的例子需要在编译过程中指定注解处理器;下面尝试将注解处理器打包,由其他工程以
jar 包形式引入,真正达到 lombok 的效果
项目结构如下
 image-20230330173700415
image-20230330173700415
在 resources/META-INF/services下新建文件
javax.annotation.processing.Processor,内容如下:
1
2
| org.example.anno.GetterProcessor
org.example.anno.SetterProcessor
|
pom.xml中加入构建方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<compilerArgument>
-proc:none
</compilerArgument>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
|
构建,生成 jar 文件
测试工程
将注解工程 jar 包引入
1
2
3
4
5
6
7
8
9
| <dependencies>
<dependency>
<groupId>org.example</groupId>
<artifactId>anno-jar</artifactId>
<version>1.0-SNAPSHOT</version>
<scope>system</scope>
<systemPath>/Users/zhangjiaming/workspace/gitlab/java-agent-demo/anno-jar/target/anno-jar-1.0-SNAPSHOT.jar</systemPath>
</dependency>
</dependencies>
|
编写测试类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| package org.example.model;
import org.example.anno.Getter;
import org.example.anno.Setter;
@Getter
@Setter
public class Dog {
private String name;
private String color;
private Integer weight;
private Boolean big;
public Dog(String name, String color, Integer weight) {
this.name = name;
this.color = color;
this.weight = weight;
}
public Dog() {
}
public static void main(String[] args) {
Dog dog = new Dog("zhangjiaming", "white", 3);
System.out.println(dog.getName());
}
}
|
编译并打包:
(运行指令报错,待研究)
运行:
1
2
| javac org.example.model.Dog
|
遇到问题
在测试工程目录下执行 mvn clean package 报错如下
 image-20230401003903758
image-20230401003903758
不过用 idea 的 maven package 工具打包成功,具体原因待研究
完整项目见 github
地址:https://github.com/Shaun2016/anno-practice
运行时注解
运行时注解,在编译时被写入字节码文件中,可以通过 JVM
运行时获取注解信息(Retention=RUNTIME)
原理
使用下面的例子方便说明
注解:TestAnnotation
注解实用类:Dog
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@interface TestAnnotation {
int level();
String desc();
}
@TestAnnotation(
level = 123,
desc = "This is a test annotation"
)
public class Dog {
}
|
- 编译 Dog.java,注解会被写入到被 Dog 类的字节码文件中
- 类加载器将被 Dog 类加载到 JVM 中,并通过 RuntimeVisibleAnnotations
等属性保存注解 key-value 关系,通过 Map 来保存
- 通过 JDK 动态代理,将注解类(本质是一个接口)生成代理对象
- 调用代理对象的对应的方法(level 和 desc 方法),会调用注解处理器的
invoke 方法
- 注解处理器从 Dog Class 对象的 RuntimeVisibleAnnotations 等属性的 Map
中找到对应的返回值
实例
1
2
3
4
5
6
| public void test1() {
Class<Dog> clazz = Dog.class;
TestAnnotation myAnnotation = clazz.getAnnotation(TestAnnotation.class);
System.out.println(myAnnotation.desc());
System.out.println(myAnnotation.level());
}
|
下文将针对运行时注解,介绍AOP相关的内容
总结
本文介绍了注解的分类:插入式注解和运行时注解,主要介绍了插入式注解的原理,为了更好的说清楚,引入了
java
的编译过程,并介绍了插入式注解在编译过程中的哪个阶段;插入式注解主要是操作了AST,JCTree
用来封装 AST 节点,TreeMaker 是操作 AST的工具,并自己模拟实现了 lombok
的 getter 和 setter 注解,最终自动生成了 getter 和 setter
方法;最后简单介绍了运行时注解的原理
引文
javac源码笔记与简单的编译原理
java
抽象语法树(AST)系列一:概述
Lombok原理分析与功能实现
Java编译时注解学习,并简单实现Lombok
3.
自定义Java编译时注解处理器
(第二讲)JVM字节码的探索与实践应用之《注解的原理与应用》