本文介绍硬件层面多 CPU 下的可见性问题,主要包括:
- cpu 的多级缓存
- 什么是可见性问题
- 缓存一致性协议 MESI
- MESI 的问题与优化
- 什么是指令重排以及指令重排产生的原因
- cpu 内存屏障
- 伪共享问题
为什么会导致 CPU 内存可见性问题
在讨论 CPU 内存可见性问题之前,首先介绍下 cpu 的多级缓存
cpu 多级缓存
来历
CPU 负责执行程序的指令,内存负责存数据。在很多年前,CPU 的频率与内存总线的频率在同一层面上,内存的访问速度仅比寄存器慢一些。但是,上世纪 90 年代 CPU 的频率大大提升,但内存总线的频率与内存芯片的性能却没有得到成比例的提升。并不是因为造不出更快的内存,只是因为太贵了,内存如果要达到目前 CPU 那样的速度,那么它的造价恐怕要贵上好几个数量级。所以,CPU 的运算速度要比内存读写速度快很多。这样会使 CPU 花费很长的时间等待数据的到来或把数据写入到内存中。所以,为了解决 CPU 运算速度与内存读写速度不匹配的矛盾,就出现了CPU缓存
概念
CPU缓存:CPU与内存之间的数据交换器,它的容量比内存小的多但是交换速度却比内存要快得多,CPU缓存一般直接跟CPU芯片集成或位于主板总线互连的独立芯片上
作用
减小相应时间:CPU往往需要重复处理相同的数据、重复执行相同的指令,如果这部分数据、指令 CPU 能在 CPU 缓存中找到,CPU 就不需要从内存或硬盘中再读取数据、指令,从而减少了整机的响应时间。
缓存的作用满足以下两种局部性原理:
- 时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
- 空间局部性(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
结构
CPU 存在三级缓存:L1, L2, L3,其中,L1 又分为 L1d (L1 Data Cache,用于存储数据) 和 L1i (L1 Instruction Cache,用于存储指令),L2 缓存比 L1 大一些,一般是每个 CPU 都有一个独立的 L2 缓存,L3 是最大的一级,在同一个 CPU 插槽的 CPU 共享一个 L3 缓存
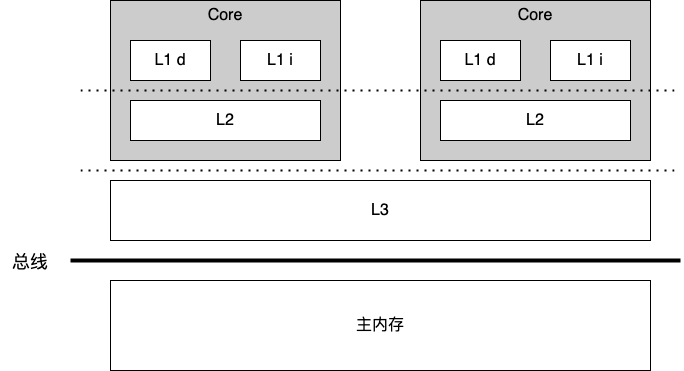
不同层级缓存读取数据速度的差异如下:
| 从CPU到 | 大约需要的CPU周期 | 大约需要的时间(单位ns) |
|---|---|---|
| 寄存器 | 1 cycle | |
| L1 Cache | ~3-4 cycles | ~0.5-1 ns |
| L2 Cache | ~10-20 cycles | ~3-7 ns |
| L3 Cache | ~40-45 cycles | ~15 ns |
| 跨槽传输 | ~20 ns | |
| 内存 | ~120-240 cycles | ~60-120ns |
速度比较:100 * L1 = 20 * L2 = 8 * L3 = 内存
CPU 获取数据,首先会在最快的缓存中找数据,如果缓存没有命中,则往下一级找,直到三级缓存都找不到,再到内存找数据
数据流
- 程序以及数据被加载到主内存
- 指令和数据被加载到 CPU 的高速缓存
- CPU 执行指令,把结果写到高速缓存
- 高速缓存中的数据写回主内存
在这个过程中,如果 CPU 在高速缓存中已经找到数据,则不会到主内存中加载,这样多个 CPU 同时工作,就可能产生同一份数据,在多个 CPU 中值不一致的问题,我们称之为内存可见性问题
为了解决内存可见性问题,有两个办法,一个是总线锁,一个是使用一致性协议
硬件层面 CPU 内存可见性问题的解决方案
总线锁
涉及共享的变量存储的时候,总线锁使用处理器提供的一个 LOCK# 信号,当一个处理器在总线上输出此信号时,对总线加锁,禁止其他线程读取内存;变量值写入到主内存变量后,才会解锁
这里是不是还要清空其他 CPU 缓存中的变量
由于总线锁会锁住整个内存,其他线程只能等待,效率太低,所以有了缓存一致性协议
缓存一致性协议有 MSI,MESI,MOSI 等,下面介绍下 MESI
CPU缓存一致性协议(MESI)
缓存行 Cache line
在 L1,L2,L3 中存储的数据不是以变量单独存储的,在每级缓存里以缓存行为单位存储,每个缓存行大小在32字节-256字节之间,缓存行大小通常为64字节(工业经验得出)
缓存每次更新都是从主存中加载连续的 64 个字节
下面介绍的 MESI 协议是基于一个 Cache line 的
MESI 协议的状态
每个 Cache line 抽出 2bit 的位置,用来表示 4 个状态:M,E,S,I
| 状态 | 含义 | 缓存行是否有效 | 数据存在位置 | 与内存数据的比较 |
|---|---|---|---|---|
| M 修改 Modified | 当前 CPU 缓存有最新数据, 其他 CPU 拥有失效数据,当前 CPU 数据与内存不一致,但以当前 CPU 数据为准 | 有效 | 只在本缓存行 | 不一致 |
| E 独享/互斥 Exclusize | 只有当前 CPU 有数据,其他 CPU 没有该数据,当前 CPU 数据与内存数据一致 | 有效 | 只在本缓存行 | 一致 |
| S 共享 Shared | 当前 CPU 与其他 CPU 拥有相同数据,并与内存中数据一致 | 有效 | 多个缓存行 | 一致 |
| I 无效 Invalid | 当前 CPU 数据失效,其他 CPU 数据可能有可能无,数据应从内存中读取,且当前 CPU 与 内存数据不一致 | 无效 | - | - |
对于 Cache line 的操作分为以下四种:
- Local Read(LR):当前 CPU 读
- Local Write(LW):当前 CPU 写
- Remote Read(RR):其他 CPU 读
- Remote Write(RW):其他 CPU 写
当前 CPU 读写表示 CPU 操作自己的缓存行,其他 CPU 读写表示 CPU 操作其他 CPU 的缓存行
MESI 是针对单个缓存行进行处理,如果数据超过一个缓存行的大小,无法使用缓存一致性对该数据控制,只能使用锁总线的方式
那么当一个缓存行对应的内存被执行上面四种操作后,缓存行的状态会发生什么变化呢?各状态的转移如下图所示
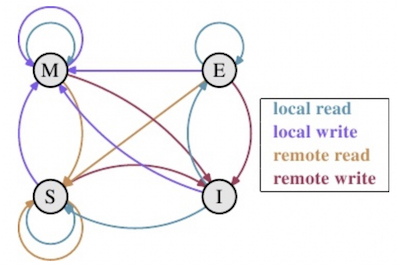
说明:
| 状态 | 操作 |
|---|---|
| Modified | LR: 当前 CPU
缓存中有最新数据,状态不变 LW: 直接修改当前 CPU 缓存,修改后仍拥有最新数据,状态不变 RR: 其他 CPU 方式读操作,为了保证一致性,当前 CPU 将数据写回内存,随后 RR 将数据通知其他 CPU 更新缓存,使其他 CPU 拥有和当前 CPU 相同的数据,状态改为 S RW: 其他 CPU 写,本缓存失效,状态改为 I |
| Exclusive | LR: 当前 CPU
缓存中独享最新数据,状态不变 LW: 修改当前 CPU 缓存值,状态改为 M RR: 其他 CPU 读后,多个 CPU 数据都与内存一致,状态改为 S RW: 其他 CPU 写操作,其他 CPU 数据为最新,当前 CPU 数据失效,状态改为 I |
| Shared | LR: 当前 CPU
读数据,状态不变 LW: 当前 CPU 写操作,并不会将数据立即写回内存,为了保证一致性,将状态修改为 M RR: 其他 CPU 读操作,因为多个 CPU 数据都与内存一致,状态不变 RW: 其他 CPU 写操作,其他 CPU 数据为最新,当前 CPU 数据失效,状态改为 I |
| Invalid | LR: 当前 CPU 读,当前缓存不可用,需读内存,若其他
CPU 无数据,当前 CPU 独享,状态改为 E;若其他 CPU 有数据且状态为
S、E,状态改为 S;其他 CPU 有数据且状态为 M,其他 CPU
先将数据写回内存,随后当前 CPU 读数据,状态改为
S LW: 当前 CPU 写,状态变为 M RR: 其他 CPU 读,与当前 CPU 缓存无关,状态不变 RW: 其他 CPU 写,与当前 CPU 缓存无关,状态不变 |
总的来说,对于 MESI 协议,从 CPU 读写角度来说会遵循以下原则:
CPU 读请求:缓存处于 M、E、S 状态都可以被读取,I 状态 CPU 只能从主存中读取数据
CPU 写请求:缓存处于 M、E 状态才可以被写。对于 S 状态的写,需要将其他 CPU 中缓存行置为无效才可写
多核缓存协同操作的过程
两个CPU同时读:
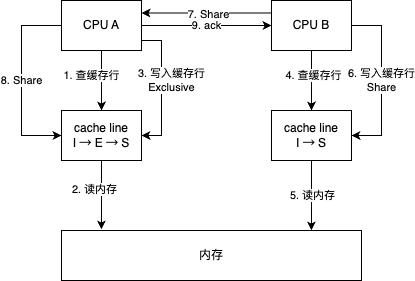
一个CPU写,一个CPU读:
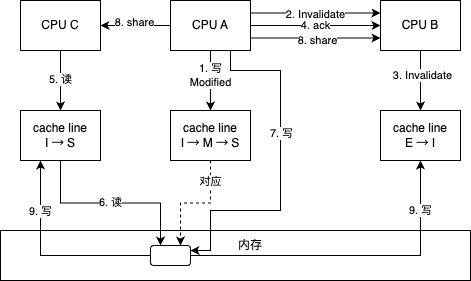
两个CPU同时写:
MESI 的问题与优化
严格按照 MESI 协议,会有严重的性能问题,如:
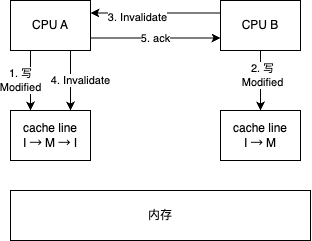
- 若 CPU0 发生 LW,首先要通知其他 CPU 将对应缓存行的状态改为 I,等待其他 CPU 的确认回执,CPU0 在这段时间内都是阻塞状态
- 若 CPU1 发生 RW,CPU0 需要将自身缓存失效并发送确认回执,当 RW 事件很多时,实时处理时效时间存在很难,会有一定的延迟
为了解决上述问题,引入了写缓冲区(Load Buffer)和失效队列(Invalid Queue)
写缓冲区(Load Buffer)
写缓冲区是属于每个 CPU 的,当使用了写缓冲区后,每当发生 LW,当前 CPU 不再阻塞地等待其他 CPU 的确认回执,而是直接将更新的值写入写缓冲区,然后继续执行后续指令
在进行 LR 时,CPU 会先在写缓冲区中查询记录是否存在,如果存在则会从写缓冲区中直接获取,这一机制即是 Store Fowarding
失效队列(Invalid Queue)
失效队列也是属于每个 CPU 的,使用失效队列后,发生 RW 对应的 CPU 缓存不再同步地将自身缓存失效并发送确认回执,而是将失效消息放入失效队列,立即发送确认回执
后续 CPU 会在空闲是对失效队列中的消息进行处理,将对应的 CPU 缓存失效
Ref:缓存一致性协议硬核讲解
指令重排
引入 Load Buffer 后,即使读写指令本身是按照顺序执行的,但最终可能乱序执行,我们称这个问题为指令重排
指令重排的原因
由于 CPU0 发现 LW 时,在通知其他 CPU 失效并等待回执的过程中是阻塞状态,影响了性能

故使用 store buffer 来优化:CPU0 在 LW 时,将内容写入 store buffer,同时通知其他 CPU 失效,然后就可以处理其他指令;当收到了所有其他 CPU 的 ack 后,再将 store buffer 中的数据写入 cache line 中。当 cache line 对应的内存发生 RR 时再将数据从 cache line 写入主存
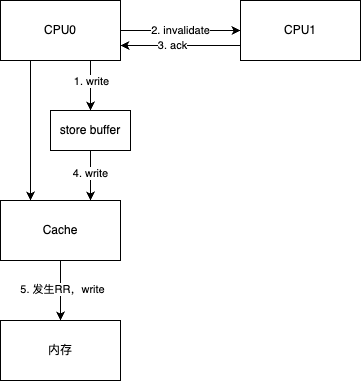
在上图的流程中,假设指令 A 是写操作(LW),指令 B 是读操作(LR);CPU 先执行 A,写的内容会先放到 store buffer,而不在内存中;执行完 A 接着执行 B,这样给外界的感觉就是,先执行了 B,后执行了 A
Ref:指令重排的原理
指令重排的验证
1 | import org.junit.Test; |
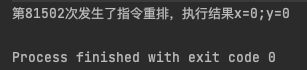
如上面的例子,如果严格按照顺序执行,无论哪个线程先被执行,x 和 y 的值必有一个为 1,结果显示却出现了 x 和 y 都为 0 的结果,只可能是两个线程内都发生了指令重排导致的
Ref:并发(三)、Java实现一段简单的会导致指令重排的例子
Ref:CyclicBarrier用法
指令重排带来哪些问题
- 并发情况下影响原有的业务逻辑
- 导致单例模式失效
对于 MESI 优化带来的问题,下面讨论在硬件层面的解决办法
CPU 内存屏障
为什么要使用 CPU 内存屏障?
MESI 原本是强一致性的,但经过优化后,弱化成最终一致性,在某些中间状态下,多个 CPU 之间的数据并不一致,还可能出现乱序执行的情况;内存屏障就是用于禁止指令重排
每种 CPU 的屏障指令是不一样,例如 Intel 的 CPU 设计中有 3 条指令:
- sfence:save fence,写屏障指令。在sfence指令前的写操作必须在sfence指令后的写操作前完成
- lfence:load fence,读屏障指令。在lfence指令前的读操作必须在lfence指令后的读操作前完成
- mfence:在mfence指令前得读写操作必须在mfence指令后的读写操作前完成
Ref:内存屏障
小节:上面介绍了 cpu 可见性问题的产生原因,可见性问题在硬件层面的解决方案,CPU 缓存一致性协议 MESI,以及 MESI 在使用写缓冲区优化性能而引发的指令重排问题
上文主要讨论了可见性问题,在硬件层面使用了缓存行 + 缓存一致性协议来解决,不过这带来了一个性能问题:伪共享问题
伪共享问题
上面提到了缓存行和缓存一致性协议,看下面的场景:
主存中有 a b 两个变量,CPU A 中的线程在对
a 修改,CPU B 的线程对 b 读取,当前者修改
a 后,会把 a 所在的缓存行写回主存,令 CPU B
中对应的缓存行失效。这时 CPU B 读取 b
时在缓存中找不到,需要从主存重新加载;
(双写的场景会咋样呢?)
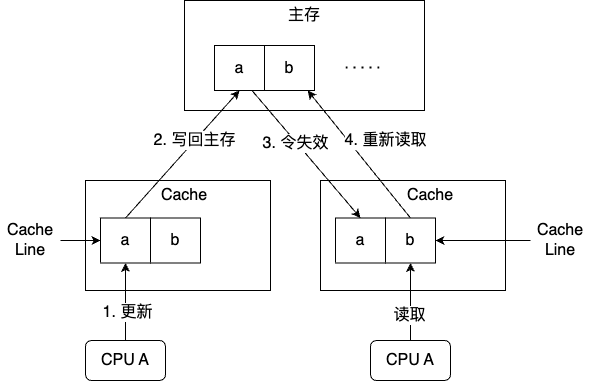
这样就出现了一个问题,b 与 a
不相关,每次却要因为 a 的更新而到主存中重新读取
当多线程修改相互独立的数据时,如果这些数据共享同一个缓存行,会无意中影响彼此的性能,这就是伪共享
伪共享的例子
1 | class Counter { |
将数据结构改为如下:
1 | class Counter { |
加入了 7 个long类型数值,使得 x 与 y
中间产生了 56 字节(一个 long 类型占 8 字节),这样保证 x
与 y 不会在一个缓存行中,而从避免了伪共享的问题