面试分享~No.2
题目:
- 【Java】JVM 内存模型【热】
- 【Java】JVM启动参数
- 【Redis】数据持久化的方式
- 【Redis】单线程速度快的原因【热】
- 【MySQL】隔离级别
- 【算法题】反转链表【热】
JVM内存模型
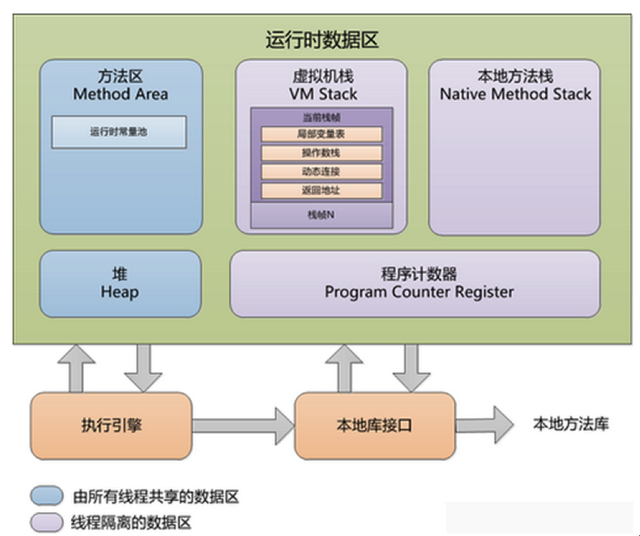
线程私有:JVM栈,本地方法栈,程序计数器
线程共有:堆,方法区
堆
方法区
存放已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据
JVM栈
栈的构成
栈中存放的是栈帧,一个方法就是一个栈帧
栈帧中包含:局部变量表,操作数栈,动态链接,方法返回地址
下面通过几个例子简述局部变量表和操作数栈
例子1:
1 | public static void main(String[] args) { |
使用jclasslib查看函数的字节码
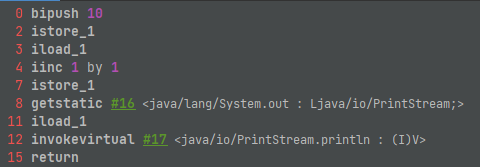
字节码的执行过程
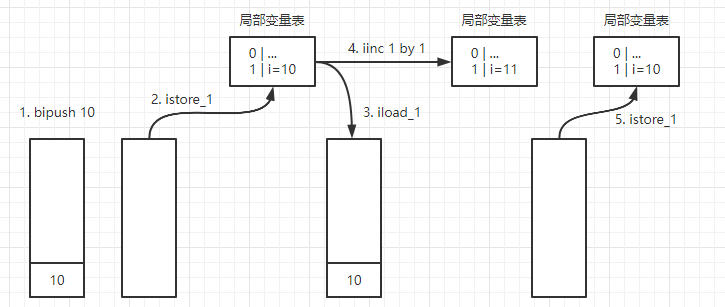
- 将10压入操作数栈
- 将操作数栈弹出,写入局部变量表位置为1的变量
- 将局部变量表位置为1的变量值压入栈
- 将局部变量表位置为1的变量值加1
- 将操作数栈弹出,写入局部变量表位置为1的变量
例子2:
1 | public static void main(String[] args) { |
字节码:
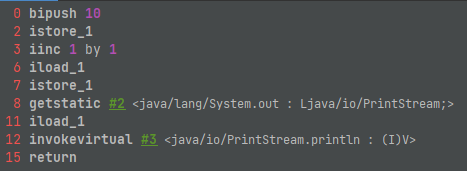
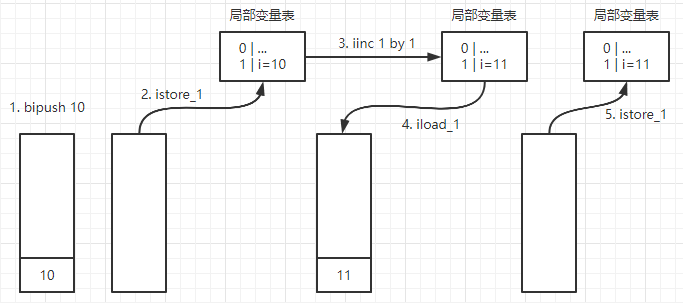
字节码执行过程:
- 将10入栈(操作数栈的简称)
- 出栈,写入局部变量表下标1的变量
- 局部变量表下标为1的变量加1
- 局部变量表下标为1的变量入栈
- 出栈,写入局部变量表下标1的变量
例子3:
1 | public int add(int a, int b, int c) { |
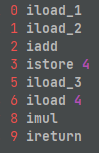
字节码执行流程:
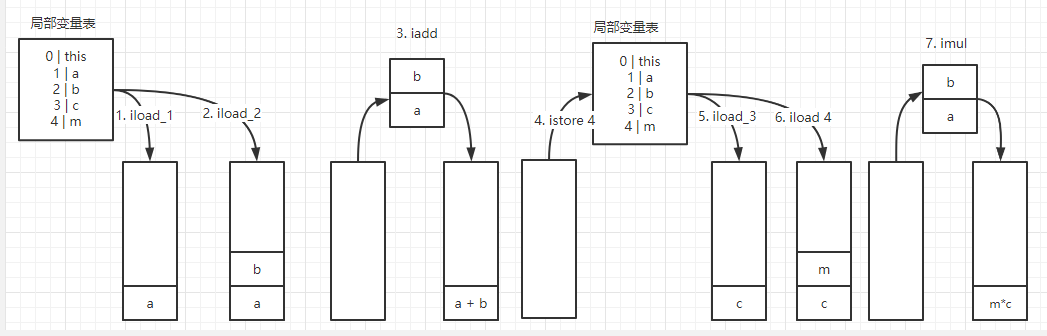
动态链接:指向常量池中的一个对象
方法返回值:栈帧弹出后,下一个栈帧执行的位置
本地方法栈
存放虚拟机使用到的 Native 方法
程序计数器
记录程序当前执行的字节码的位置
https://blog.csdn.net/m0_71777195/article/details/126247090
JVM常用启动参数
| 参数 | 说明 |
|---|---|
| -Xmx3000m | 设置JVM堆最大空间为3000M |
| -Xms3000m | 设置JVM堆初始大小为3000M,建议与Xmx值相同 |
| -Xss | 设置线程栈大小 |
| -XX:NewSize=1024m | 设置年轻代初始值为1024M |
| -XX:MaxNewSize=1024m | 设置年轻代最大值为1024M |
| -XX:-PrintGC | 每次GC打印日志 |
Ref: https://blog.csdn.net/LC181119/article/details/122972834
Redis 数据持久化方式
RDB (Redis DataBase)
将某一时刻的数据(快照)持久化到磁盘
RDB文件的创建:SAVE,BGSAVE
其中,SAVE会阻塞服务进程,导致服务无法处理任何请求;BGSAVE不会阻塞服务进程,而是fork一个子进程,由子进程创建RDB文件
RDB文件的载入
服务器启动时自动执行
RDB的执行周期
默认配置:
save 900 1900秒内执行一次
由于RDB是周期性的,如果服务突然挂了,最新的数据就会丢失
AOF (Append Only File)
将写命令写到日志中
AOF的实现
- 命令追加:将命令追加到AOF缓冲区末尾
- 文件写入:将AOF缓存区内容写入到日志文件缓存区
- 文件同步:将日志文件缓存区写入磁盘
flushAppendOnlyFile
每个事件执行之后,都会调用flushAppendOnlyFile函数,考虑是否需要将aof_buf内容写入和同步到AOF日志中,flushAppendOnlyFile函数的行为由服务配置的appendfsync选项值来决定:
| appendfsync值 | flushAppendOnlyFile行为 |
|---|---|
| always | 将aof_buf所有内容写入并同步到AOF文件 |
| everysec(默认) | 将aof_buf所有内容写入AOF文件,如果上次同步AOF文件的时间距离超过1秒,对AOF文件进行同步 |
| no | 将aof_buf所有内容写入AOF文件缓冲区,不对AOF文件磁盘进行同步,何时同步由操作系统来决定 |
AOF 文件重写
解决AOF文件体积膨胀的问题,将一些冗余指令合并,缩小文件体积
实现方式:
读取、分析AOF文件的效率低,Redis采用的方式为:直接读当前数据,这样存在问题是,操作过程中进来的指令无法写入到新的AOF文件中,如何不阻塞主进程
Redis 将AOF重写的操作放到子进程中执行(为啥不能是线程中,而是fork一个进程)
目的是:
- 子进程进行 AOF 重写期间,服务器(父进程)可以继续处理命令请求
- 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性(Why)
如何解决AOF重写过程中遗漏的指令
- 创建子进程后,将指令写入到AOF重写缓冲区
- 子进程完成AOF重写后,向父进程发送一个信号,父进程收到信号后,不处理请求,执行:
- 将AOF重写缓冲区的内容写入新的AOF文件
- 对新的AOF文件重命名,覆盖旧的AOF文件
- 父进程继续处理请求
上述过程中,第2步会阻塞请求的执行
Ref:
https://zhuanlan.zhihu.com/p/55236400
https://blog.csdn.net/weixin_44743841/article/details/107915188
Redis 单线程速度快的原因
- 基于内存,底层采用了高效的数据结构,比如哈希表、跳表
- 单线程避免了上下文切换
- 避免共享资源加锁导致的性能损耗
- 采用多路复用的IO模型(epoll)
- 非CPU密集型任务,Redis的大部分操作瓶颈在内存和网络带宽
Ref: https://blog.csdn.net/m0_67401134/article/details/123862847
MySQL 事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(Read uncommitted) | √ | √ | √ |
| 读提交(read committed) | × | √ | √ |
| 可重复读(repeatable read) | × | × | √ |
| 串行化(Serializable) | × | × | × |
MySQL 语句的默认事务隔离级别:RR
可重复读,通过SELECT @@transaction_isolation;查看
修改隔离级别:SET SESSION transaction_isolation = 'READ-UNCOMMITTED';
引发问题:
如何实现RR隔离级别
使用MVCC来实现可重复读,实现原理为:
依赖于记录中的三个隐藏字段(row_id,trx_id, rollback_ptr),undo log,read view
trx_id:该记录最新修改的事务号
rollback_ptr:上一个版本指针
undo log:回滚日志
read view:可见性
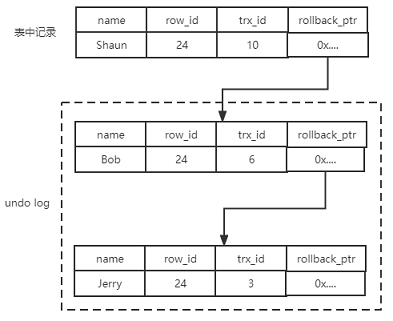
如上图,事务5来读取某一行数据,如那行数据的row_id=24,记录中trx_id > 5,对事务5不可见,通过rollback_ptr在undo log中找上个版本的记录,发现trx_id > 5,再找上个版本的记录,发现trx_id < 5,则该记录是事务5可见的最新版本,读数据
MVCC 下的两种读方式
当前读:从数据表中,不同语句根据隔离级别,使用悲观锁处理冲突,如select ... in share mode,select ... for update
快照读:使用MVCC,从表或undo
log中读数据,不需要使用悲观锁,如select ...
RR是通过快照读来实现可重复读
反转链表
要求:空间复杂度O(1),时间复杂度O(n)
1 | public void reverseLinkedList(Node head) { |