面试题分享~ No.1
题目:
- 【Java】线程池如何使用,参数有哪些【必问】
- 【Java】强引用、弱引用的区别和应用
- 【MySQL】如何优化慢SQL【必问】
- 【MySQL】索引失效的场景
- 【MySQL】Innodb 索引的数据结构是什么,为什么
- 【Redis】key的TTL如何实现
- 【Redis】缓存穿透的解决方案
- 【算法题】如何动态找中位数
线程池如何使用,参数有哪些
结合项目,哪个业务用了线程池
参数说明:
1 | public ThreadPoolExecutor(int corePoolSize, // 核心线程数 |
corePoolSize:线程池长期维持的线程数,不会回收
maximumPoolSize: 线程数上限
keepAliveTime:非核心线程的存活时间,超过该时间被回收
unit:收回时间的单位
workQueue:任务的工作队列(队列的最大长度默认值看源码:Integer.MAX_VALUE=2^23-1)
threadFactory:生产新线程的工厂
handler:拒绝策略
为什么要用线程池
- 降低资源消耗:使用单独的线程需要频繁创建和销毁线程,线程池可以复用已创建的线程
- 提高相应速度:当任务到达时,不需要等线程创建,就可以执行
- 提高资源的管理:控制创建线程的数量
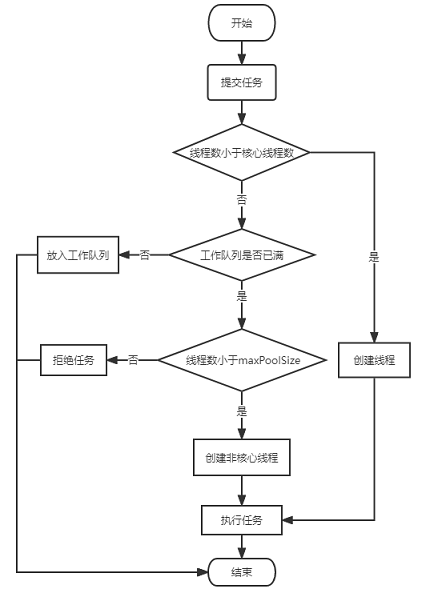
线程池中任务的执行流程
见 ThreadPoolExecutor.java 中 execute 函数
- 当线程池中线程数小于corePoolSize,直接执行
- 当线程数大于等于 corePoolSize,则将任务放入 workQueue,随着线程池中核心线程们不断执行任务,只要有空闲的线程,就从workQueue中取任务并执行
- 当 workQueue 已满,放不下新的任务,则新建非核心线程入池并处理,直到线程数达到 maximumPoolSize
- 如果线程池中线程数大于 maximumPoolSize 则使用拒绝策略拒绝处理
拒绝策略
| 策略 | 说明 |
|---|---|
| ThreadPoolExecutor.AbortPolicy | 抛出异常 |
| ThreadPoolExecutor.CallerRunsPolicy | 重试 |
| ThreadPoolExecutor.DiscardPolicy | 丢弃当前任务 |
| ThreadPoolExecutor.DiscardOldestPolicy | 丢弃工作队列头部任务 |
线程池的种类
Executors线程池工具类为我们提供了一些API用于返回不同类型的线程池
| 类型 | 说明 |
|---|---|
| CachedThreadPool | 线程数无上限,可以接收无上限的任务 |
| FixedThreadPool | 线程数固定,可以接收无上限的任务 |
| ScheduledThreadPool | 定期执行任务 |
| SingleThreadExcutor | 只有一个线程 |
例子
1 | package com.zjm.thread; |
Ref:https://www.cnblogs.com/kxxiaomutou/p/15968431.html
强引用、弱引用的区别和应用
| 引用类型 | 创建方式 | 特点 |
|---|---|---|
| 强引用 | Object o = new Object(); | 如果有根对象指向它,触发GC时,不会回收这类对象;如果没有根对象指向它,会被GC收回 |
| 弱引用 | SoftReference |
当内存空间不足的时候,如果就会回收这些对象 |
| 软引用 | WeakReference |
不管当前内存空间是否足够,都会回收 |
引发问题:
- 怎么判断一个强引用对象是否可以被回收
- 哪些对象是根对象
- 弱引用的应用
如何优化慢SQL
开启慢SQL统计:
1
2
3set global slow_query_log=on; // 开启慢SQL统计
set global long_query_time=1; // 设置超过1s的请求为慢SQL查看执行计划,判断是否走到索引
如何查看执行计划:
explain select ... from ... where ...关注执行计划中的type字段:
type类型 说明 ALL 全表扫描 INDEX 全索引扫描 range 索引范围查询 ref 使用普通索引或唯一索引的部分前缀,可能找到多个符合条件的记录 eq_ref primary key或unique key索引 const 最多只有一行记录匹配。当联合主键或唯一索引的所有字段跟常量值比较时,join类型为const system 表中只有一行数据或者是空表,这是const类型的一个特例,且只能用于myisam和memory 根据查询计划,查看实际使用的索引
查看key字段
如果没有走到索引,分析原因
- 没有建立索引:创建对应的索引(考虑回表、索引下推的优化)
- 建了索引,而索引失效:分析索引失效的原因
索引失效的场景
在查询条件中:
- 联合索引中忽略了最左匹配原则
- 前缀模糊查询:like '%baidu'
- 使用了不等号
- 使用了表达式、函数操作,如MONTH(create_time)
- 索引是否有区分度
- 大量子查询
常见的优化策略
- 不返回不必要的字段,增加索引覆盖的概率(不刻意的建立联合索引可能蒙中索引覆盖吗...)
- 减少子查询(子查询会创建临时表,查询完毕删除临时表)
- 调整where子句的连接顺序,将过滤数据多的条件放在前面,最快速度缩小结果集(MySQL不会自己优化吗)
- 一次查询的结果最好不要过大,分页查询
- 在推理索引错误的情况下,可以强制命中一个索引
Ref:https://blog.csdn.net/y1250056491/article/details/125465583
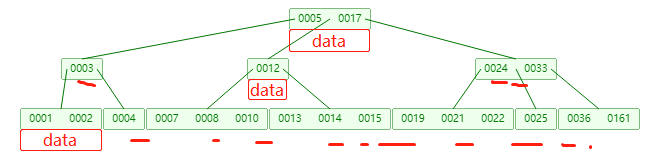
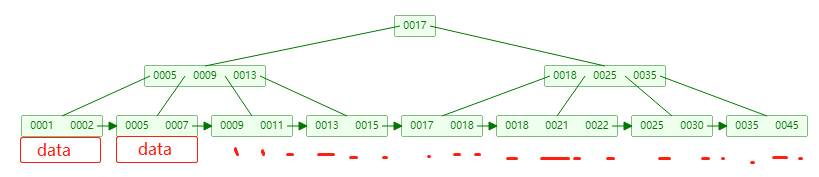
Innodb 索引的数据结构是什么,为什么
前置知识:Innodb每次IO读取的数据是16kb
对索引可以用到的数据结构进行对比:
哈希表、二叉平衡树、AVL树、红黑树、B树、B+树
对比:
数据结构 优点 缺点 哈希表 等值查询O(1)复杂度; 范围查询需要全量遍历 二叉平衡树、AVL树、红黑树 查询时间复杂度为O(logn),比B树和B+树的时间复杂度低 因为高,与磁盘的IO次数多 B树 与磁盘的IO次数比平衡树低 数据在所有节点上,导致每个数据页能存放的向下指针(就是degree)是较少的(一个数据页大小固定为16kb),导致树高度增大,IO次数增多 B+树 数据仅在叶子节点上,每个数据页可以存放更多的指针,使得树高度降低,IO次数降低;由于数据都在叶子节点,范围查询更快 时间复杂度比平衡树和B树要低
B树
B+树
Ref:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
key的TTL如何实现
主动失效
定时任务周期性执行:
从有失效机制的Key中随机取出20个key
删除已过期的key
判断是否超过1/4的key已经失效,如果没有,执行第i步
被动失效
当客户端获取key时,判断key是否失效
Ref:https://blog.csdn.net/m0_37939214/article/details/107794344
缓存穿透的解决方案
简述什么是缓存穿透
解决方案:
- 缓存空值
- 布隆过滤器
【引发问题】如果在高并发场景中,一个数据库中不存在的key,布隆过滤器漏了过去(存在误判),缓存中还没有设置空值,由于redis是串行计算的,在设置空值之前会有大量请求打到数据库,对DB造成压力,如何解决
发现缓存中没有,先争抢一把锁,谁抢到再访问DB,设置空值,没有抢到的返回用户【sorry,请重试】
Ref:https://blog.csdn.net/a898712940/article/details/116212825
数据流中的中位数
对顶堆
思路:
个数为奇数时,应该往大顶堆插入,需要判断要插入的数据,是否大于小顶堆的堆顶元素,说明小堆顶的对顶元素应该出队,入队大顶堆中,而要插入的数据实际应该入队小顶堆;
个数为偶数时,应该往小顶堆插入数据,需要判断,要插入的数据,是否小于大顶堆的堆顶元素,说明大堆顶的元素要出队,入队小顶堆中,而要插入的数据实际应该入队大顶堆;
Ref:https://www.jianshu.com/p/f7e2ed52052d