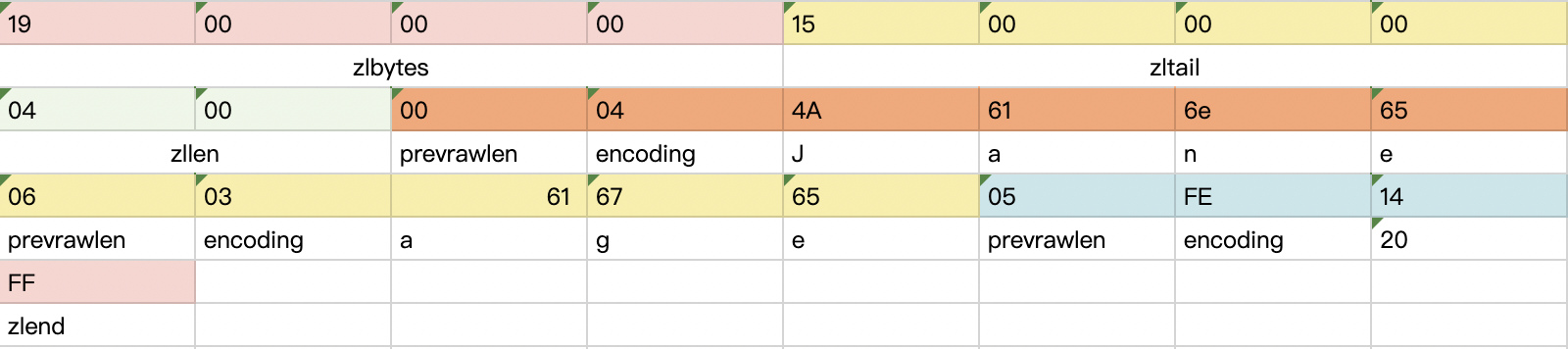
/* Fills a struct with all information about an entry. * This function is the "unsafe" alternative to the one below. * Generally, all function that return a pointer to an element in the ziplist * will assert that this element is valid, so it can be freely used. * Generally functions such ziplistGet assume the input pointer is already * validated (since it's the return value of another function). */ staticinlinevoidzipEntry(unsignedchar *p, zlentry *e) { ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen); ZIP_ENTRY_ENCODING(p + e->prevrawlensize, e->encoding); ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len); assert(e->lensize != 0); /* check that encoding was valid. */ e->headersize = e->prevrawlensize + e->lensize; e->p = p; }
/* Different encoding/length possibilities */ #define ZIP_STR_MASK 0xc0 #define ZIP_INT_MASK 0x30 #define ZIP_STR_06B (0 << 6) #define ZIP_STR_14B (1 << 6) #define ZIP_STR_32B (2 << 6) #define ZIP_INT_16B (0xc0 | 0<<4) #define ZIP_INT_32B (0xc0 | 1<<4) #define ZIP_INT_64B (0xc0 | 2<<4) #define ZIP_INT_24B (0xc0 | 3<<4) #define ZIP_INT_8B 0xfe /* 4 bit integer immediate encoding |1111xxxx| with xxxx between * 0001 and 1101. */ #define ZIP_INT_IMM_MASK 0x0f /* Mask to extract the 4 bits value. To add one is needed to reconstruct the value. */ #define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */ #define ZIP_INT_IMM_MAX 0xfd /* 11111101 */
/* Insert item at "p". */ unsignedchar *__ziplistInsert(unsignedchar *zl, unsignedchar *p, unsignedchar *s, unsignedint slen) { size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen; unsignedint prevlensize, prevlen = 0; size_t offset; int nextdiff = 0; unsignedchar encoding = 0; longlong value = 123456789; /* initialized to avoid warning. Using a value that is easy to see if for some reason we use it uninitialized. */ zlentry tail;
/* Find out prevlen for the entry that is inserted. */ if (p[0] != ZIP_END) { ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); } else { unsignedchar *ptail = ZIPLIST_ENTRY_TAIL(zl); if (ptail[0] != ZIP_END) { prevlen = zipRawEntryLength(ptail); } }
/* See if the entry can be encoded */ if (zipTryEncoding(s,slen,&value,&encoding)) { /* 'encoding' is set to the appropriate integer encoding */ reqlen = zipIntSize(encoding); } else { /* 'encoding' is untouched, however zipStoreEntryEncoding will use the * string length to figure out how to encode it. */ reqlen = slen; } /* We need space for both the length of the previous entry and * the length of the payload. */ reqlen += zipStorePrevEntryLength(NULL,prevlen); reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to * make sure that the next entry can hold this entry's length in * its prevlen field. */ int forcelarge = 0; nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0; if (nextdiff == -4 && reqlen < 4) { nextdiff = 0; forcelarge = 1; }
/* Store offset because a realloc may change the address of zl. */ offset = p-zl; zl = ziplistResize(zl,curlen+reqlen+nextdiff); p = zl+offset;
/* Apply memory move when necessary and update tail offset. */ if (p[0] != ZIP_END) { /* Subtract one because of the ZIP_END bytes */ memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */ if (forcelarge) zipStorePrevEntryLengthLarge(p+reqlen,reqlen); else zipStorePrevEntryLength(p+reqlen,reqlen);
/* Update offset for tail */ ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take * "nextdiff" in account as well. Otherwise, a change in the * size of prevlen doesn't have an effect on the *tail* offset. */ zipEntry(p+reqlen, &tail); if (p[reqlen+tail.headersize+tail.len] != ZIP_END) { ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff); } } else { /* This element will be the new tail. */ ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl); }
/* When nextdiff != 0, the raw length of the next entry has changed, so * we need to cascade the update throughout the ziplist */ if (nextdiff != 0) { offset = p-zl; zl = __ziplistCascadeUpdate(zl,p+reqlen); p = zl+offset; }
/* Write the entry */ p += zipStorePrevEntryLength(p,prevlen); p += zipStoreEntryEncoding(p,encoding,slen); if (ZIP_IS_STR(encoding)) { memcpy(p,s,slen); } else { zipSaveInteger(p,value,encoding); } ZIPLIST_INCR_LENGTH(zl,1); return zl; }