本文介绍 JVM 中的垃圾收集器
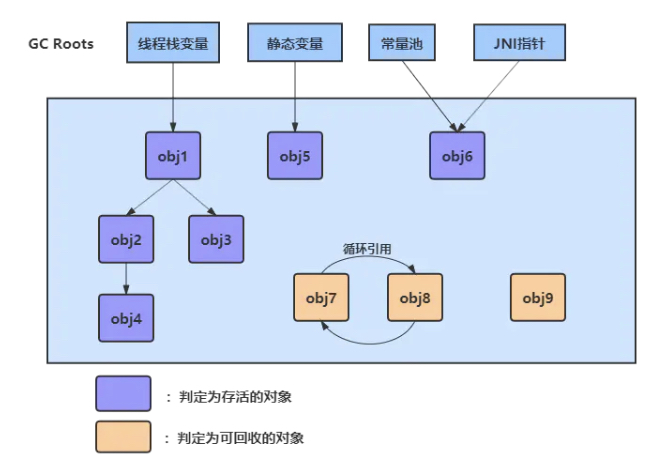
什么是垃圾
没有引用指向的一个对象或者多个对象(循环引用)
1 | // 例子:循环引用的垃圾 |
判断垃圾的方法
- 引用计数:统计每个对象的引用个数,引用计数为0,标记为垃圾,存在循环引用的问题
- 根可达算法:从GC Roots的对象开始遍历,可以达到的对象标记为存活,不可到达的对象标记为垃圾
根对象有哪些?
- 虚拟机栈中的引用(栈桢中的本地变量表)指向的对象
- 方法区中静态引用指向的对象
- 方法区中常量池中引用指向的对象
- 本地方法栈 JNI 引用的对象
还有一些不太理解的,没有一一列举
GC常用垃圾清除算法
标记清除
mark sweep
容易产生碎片,效率偏低(扫描两遍,标记一遍,清除一遍)
Q:为什么需要扫描两遍,为什么不能一边标记,一边清除?
A:因为标记的是存活对象,从根对象开始找,找到不可回收的,然后再遍历一遍,发现没有被标记的再清理;如果标记的是垃圾,则一遍就可以了,不过引用计数是存在循环引用的问题的,所以不能这么做
拷贝
copying
没有碎片,浪费空间,效率较高(扫描一遍)
从 GC Root 找到有用的对象,然后拷贝到另一边,从而引用的值也随之改变
标记压缩
mark compact
没有碎片,效率偏低(扫描两遍,移动内存,调整指针)
从 GC Root 找到有用的对象,然后将有用的对象压缩到一起
逻辑分代模型
注:仅用于逻辑分代的垃圾回收器
除 Epsilon ZGC Shenandoah 之外的GC都是使用逻辑分代模型
G1是逻辑分代,物理不分代,除此之外不仅逻辑分代,而且物理分代
新生代 + 老年代 + 永久代 Perm Generation(1.7)/元数据区 Metaspace(1.8)
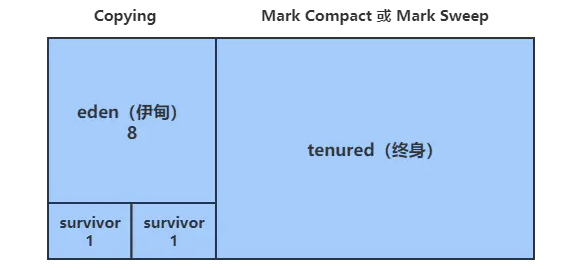
| 分代区域 | 大小 | GC算法 | 存放的对象 | GC |
|---|---|---|---|---|
| 新生代 | 方法1: 通过 -Xmn256m 设置,同 -XX:NewSize=256m -XX:MaxNewSize=256m;方法2: 通过 -XX:NewRatio=3 设置,新生代:老年代=1:3 | Copying | 年龄小于XX:MaxTenuringThreshold的对象 | Young GC(Minor GC) |
| 老年代 | 堆减去新生代大小 | mark compact | 年龄超过XX:MaxTenuringThreshold的对象(最大15,用4bit表示) | Full GC(Major GC) |
| 永久代(1.7) | 通过-XX:PermSize=128m -XX:MaxPermSize=512m 指定 | 字符串常量,Class对象 | Full GC | |
| 元数据(1.8+) | 不属于JVM内容,使用本地内存,也可以通过JVM参数限制 -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m | 不需要GC |
- 老年代装满了触发Full GC
- 永久代存放元数据,如Class对象
- 永久代必须指定大小限制,元数据区可以不设置,受物理内存限制
- 字符串常量在1.7中放在永久代,在1.8中在堆中
- MethodArea 是一个逻辑概念,代指永久代和元数据
- 对象何时进入老年代
- YGC 达到一定年龄后,Parallel Scavenge 15,CMS 6,G1 15
- 动态年龄:s1 + eden 存活的对象放到 s2,超过 s2 空间的 50%,把年龄最大的放到老年代
对象的分配过程
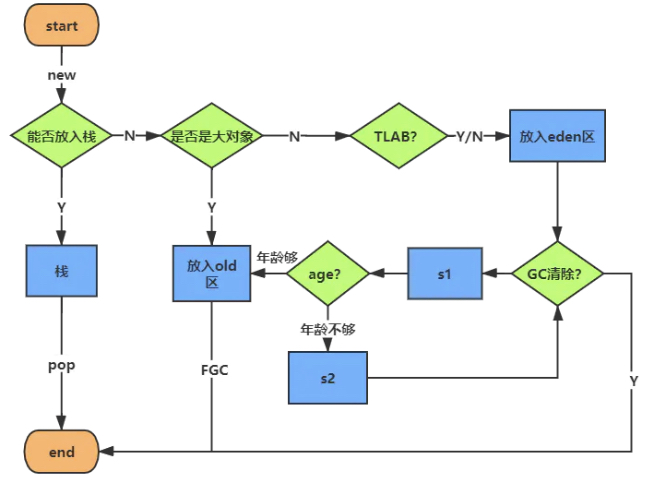
流程:
- 首先尝试在栈上分配
- 如果栈上分配不下
- 属于大对象,放到堆的老年代
- 不属于大对象,尝试线程本地分配(TLAB:Thread Local Allocation Buffer)
- 如果线程本地分配失败,放到堆的年轻代的Eden区
什么是大对象?
可以通过 -XX:PretenureSizeThreshold=5m指定,但仅用于 Serial 和 ParNew
栈上分配
- 线程私有
- 小对象
- 无逃逸
- 支持标量替换
什么是标量替换
标量是指不可再分的原始数据类型(int、long等数值类型及reference类型等)
2
System.out.println("point x=" + point.x + ", y=" + point.y);当point对象在后面的执行中未被用到,编译后会变成类似下面的结构:
2
3
int y = 2;
System.out.println("point x=" + x + ", y=" + y);从而不去创建对象,减少了创建对象和GC的成本
线程本地分配 TLAB
TLAB(Thread Local Allocation Buffer)
TLAB是虚拟机在堆内存的划分出来的一块专用空间,是线程专属的。在TLAB启动的情况下,在线程初始化时,虚拟机会为每个线程分配一块TLAB空间,只给当前线程使用,这样每个线程都单独拥有一个空间,如果需要分配内存,就在自己的空间上分配,这样就不存在竞争的情况,可以大大提升分配效率
堆上分配
分配到堆的年轻代的Eden区
垃圾回收器
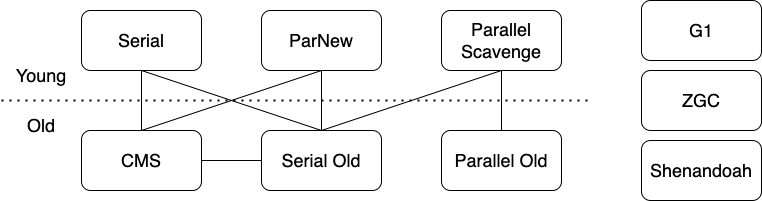
| 垃圾收集器 | 是否分代 | 是否多线程 | 是否存在和工作线程同时工作 | 使用的算法 |
|---|---|---|---|---|
| Serial | Young | 否 | 否 | copying |
| Parallel Scavenge | Young | 是 | 否 | copying |
| ParNew | Young | 是 | 否 | copying |
| Serial Old | Old | 否 | 否 | Mark-sweep Or Mark Compact |
| Parallel Old | Old | 是 | 否 | Mark Compact |
| CMS | Old | 是 | 是 | 三色标记 + Incremental Update + Mark-sweep |
| G1 | Young + Old | 是 | 是 | 三色标记 + SATB |
| ZGC | 不分代 | 是 | 是 |
CMS 与 Parallel Old 的最大区别是什么?
CMS 的某个阶段可以和工作线程同时进行,不是全程STW;Parallel Old 是多线程运行,但是全程STW
分代模型垃圾收集器的常见组合
| 垃圾收集器组合 | 特点 |
|---|---|
| Serial + Serial Old | 单线程 |
| Parallel Scavenge + Parallel Old | 多线程 |
| ParNew + CMS | 多线程 + 并发回收(与工作线程同时进行) |
Serial,Serial Old,Parallel Scavenge,Parallel Old的执行比较简单,就是在年轻代或老年代执行相对的算法
下面主要介绍 CMS 和 G1 两款垃圾收集器的流程
CMS
执行流程
阶段1. 初始标记
从 GC Roots 遍历,找到直接可达的老年代对象,发生 STW
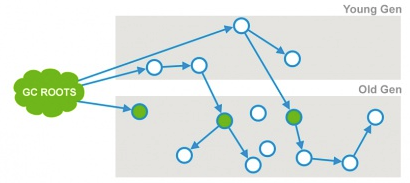
阶段2. 并发标记
GC 线程和工作线程同时执行,不产生 STW
从第一阶段标记的存活对象开始,继续向下遍历老年代,标记所有可达的老年代对象
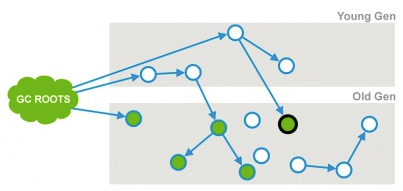
在并发标记阶段,工作线程也在执行,所以可能产生新的对象或新的垃圾
对于这些对象,需要重新标记以防被遗漏,本阶段会把这些发生变化的对象标记为 Dirty,后续只需要扫描这些 Dirty 对象,不需要扫描整个老年代
阶段3. 重新标记
来解决并发标记过程中产生的引用关系变化,需要 STW
主要工作:
- 遍历新生代对象,重新标记;(新生代会被分块,多线程扫描)
- 根据 GC Roots,重新标记;
- 遍历老年代的 Dirty 对象,重新标记
阶段4. 并发清理
并发执行 mark-sweep,清理所有未被标记的对象,不 STW
CMS 存在的问题
- 碎片化:mark-sweep 导致,如果无法分配,会使用 Serial Old 单线程的清理,导致严重的STW
- 产生浮动垃圾:阶段 4 还会产生垃圾,不会被清理
G1
设计思想
分治
经典的垃圾收集器都是对整个新生代或老年代进行垃圾回收,要扫描的对象太多了
G1采用了开创性的局部收集的设计思路和以 Region 为基本单位的内存布局方式,它将堆空间划分成多个大小相等的独立区域(Region),JVM目标是总共不超过2048个Region
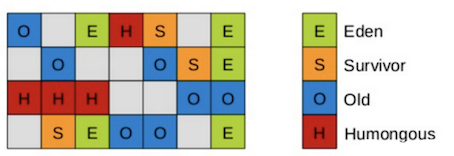
Region分为四种类型:Eden、Survivor、Old、Humongous
新生代:Eden + Survivor,默认大小为堆的5%,最大为堆的60%,Eden 和 Survivor1,Survivor2 的比例为 8:1:1
老年代:Old
Humongous:超过一个Region大小的50%的对象
新生代和老年代的比例是动态的,不需要指定
G1 会根据STW时间来调整新老代的比例
G1 的垃圾回收过程
Young GC
触发条件:Eden区放满,或者
G1计算回收时间接近参数-XX:MaxGCPauseMills设定的值,那么就会触发
Young GC
回收对象:Eden区的垃圾
过程:将存活的 Eden Region 的对象拷贝到 Survior Region,达到晋升年龄的就晋升到老年代Region,清空原Eden Region
Mixed GC
触发条件:老年代的堆空间内存占用达到了参数-XX:InitiatingHeapOccupancyPercent设定的值,默认是
45%
回收对象:所有新生代 + 部分老年代 + Homongous(根据优先级和设置的回收期望时间)
Mixed GC 的过程如下:
- 初始标记:暂定所有线程(STW),记录 GC Roots 能直接引用的对象,速度很快。(与CMS的初始标记相同)
- 并发标记:与工作线程一起工作,并发地进行可达性分析(与CMS的并发标记一样)
- 最终标记(重新标记):需要暂定所有线程(STW),根据三色标记 + SATB算法修复一些引用的状态(与CMS的标记算法不同)
- 筛选回收:筛选回收阶段会对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿STW时间来制定回收计划,使用 Copying 算法,将一个Region中的存活对象移动到另一个空的Regin中,然后将之前的Region内存空间清空(相比于CMS内存碎片化程度降低很多,但依旧有碎片出现)
如何制定回收计划?
比如此时有1000个Region都满了,但根据用户设置的STW时间,本次垃圾回收只能停顿200毫秒,那么通过之前的回收成本计算(怎么计算?),200毫秒只能回收600个Region的内存空间,那么G1就会只回收这600个Region(Collection Set,要回收的Region集合)的内存空间,尽量把GC的停顿时间控制在用户指定的停顿时间内
Full GC
触发条件:无法分配对象
回收对象:全部垃圾
过程:使用单线程/多线程(jdk1.10后多线程)标记、清理和压缩整理
如何避免 G1 的 Full GC
- 扩内存
- 提高 CPU 个数和性能
- 降低 Mixed GC 触发的阈值,让 Mixed GC 提前触发
CMS 与 G1 的并发标记算法
CMS 和 G1 最大的相同点便是它们的主要步骤都是:
- 初始标记(inital marking)
- 并发标记(concurrent marking)
- 最终标记(final marking/remark)
- 清理(cleanup)
虽然标记过程类似,但其中对于并发标记过程中对象引用状态改变的处理是不同:
CMS 使用的是三色标记 + Incremental Update 算法
G1 使用的是三色标记 + Snapshot At The Begining(SATB)算法
三色标记
黑色:自身和成员变量均已标记完成 灰色:自身被标记完成,成员变量未被标记 白色:未被标记的对象(垃圾)
扫描的过程
- 并发标记前都是白色对象
- 并发标记开始,所有能被 GC Roots 对象直达的对象被压到栈中,待向下搜索,标记为灰色
- 灰色对象依次出栈,搜索其子对象,子对象标记为灰色,入栈
- 当所有子对象都标记为灰色后,该对象标记为黑色
- 并发标记结束后,灰色对象都没了,剩下的黑色对象为存活对象,白色对象为垃圾
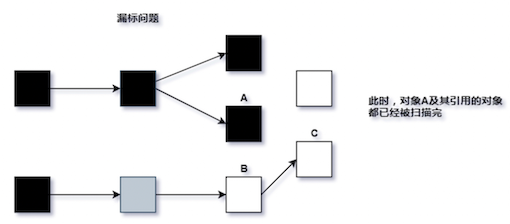
扫描过程中由于引用关系的变化,会发生漏标和多标两种情况
漏标的产生
在并发标记过程中,导致对象被漏标的两个充要条件是:
- 插入了从 black 对象到 white 对象的引用
- 删除了所有从 grey 对象到 white 对象的直接或者间接引用
举个栗子
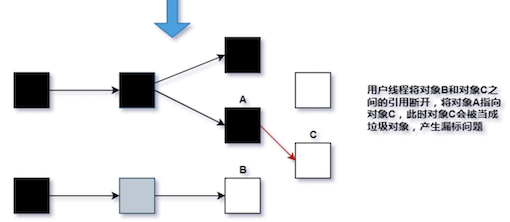
在并发标记过程中,有一个新对象 A(白色)进入了老年代,它是灰色对象 C 的属性,这时重新扫描是可以通过 C 找到 A 的,但是在并发标记过程中,A - C 的引用断了,又建立了一个黑色对象 B 到 A 的关系,导致 A 被漏标
Q:第二个条件,为什么一定要白色对象失去灰色对象到达它的引用路径呢?一个新加入到老年代的对象,没有灰色对象的引用,不会产生漏标吗?比如:在并发标记过程中,有一个新对象 A(白色)进入了老年代,一个黑色对象 B 中的引用指向了 A,并且 A 的引用指向了 null,那么我们只能从 B 找到 A了,由于 B 是已标记的,不会被重新扫描,导致了 A 被漏标,误认为垃圾,惨遭清理 :cry:
A:针对并发标记过程中产生了新对象,直接全部当成黑色,本轮不会进行清除
为了解决漏标的问题,CMS 使用了 Incremental Update,G1 使用了 SATB(Snapshot at the begining)
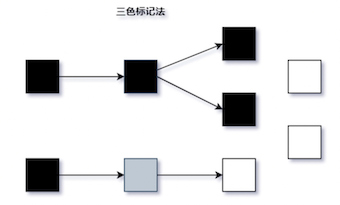
漏标的解决方案
Incremental Update
Incremental Update 关注的是第一个条件的打破,即引用关系的插入。Incremental update 利用 write barrier 将所有新插入的引用关系都记录下来(如黑A-白C),最后以这些引用关系的 src 为根 STW 地重新扫描一遍即避免了漏标问题
SATB
关注的是第二个条件的打破,即引用关系的删除。SATB 利用 pre write barrier 将所有被删除的引用关系(如灰 B-白 C)推到 GC 的堆栈,保证 C 还能被 GC 扫描到,在最终标记阶段扫描这些记录
简单的讲,当引用关系变动时,Incremental Update 把黑色对象标记为了灰色,SATB 把白色对象收集到堆栈中
两种漏标解决方案的对比:
Incremental Update算法关注的是引用的增加(A->C 的引用)
SATB算法关注的是引用的删除(B->C 的引用)
多标的产生
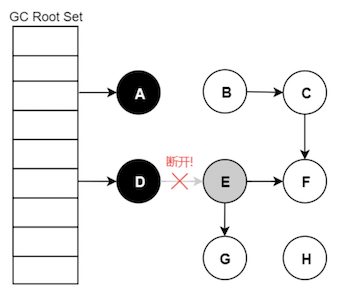
假设已经遍历到 E,E 变为灰色了,此时应用执行了
D.E = null
对象 E、F、G 是应该被回收的,但由于 E 变为灰色,其仍会被当作存活对象继续遍历下去 最终的结果是: E、F、G 仍会被标记为存活,即本轮 GC 不会回收这部分内存
这部分本应该回收但是没有回收到的内存,被称之为浮动垃圾 浮动垃圾并不会影响应用程序的正确性,只是需要等到下一轮垃圾回收中才被清除
问题汇总
对于上面的描述,有以下几个问题
问题1. SATB 将白色对象放入堆栈后,怎么重新标记白色对象?
最直接的思路,可以从 GC Roots 重新遍历一遍,看有没有遍历到白色对象,但这样效率较低
有没有更高效的思路呢,可以建立对象引用的倒排索引,即一个对象被谁引用了
看下 G1 是如何实现的,先介绍下 Card Table 和 Remember Set
Card Table
Card Table 是一个数组,每个元素称为卡片/卡页(Page),一个 Page 的大小为 1 字节。这个 Card Table 会映射整个堆空间,每个 Page 会对应堆的 512B 空间
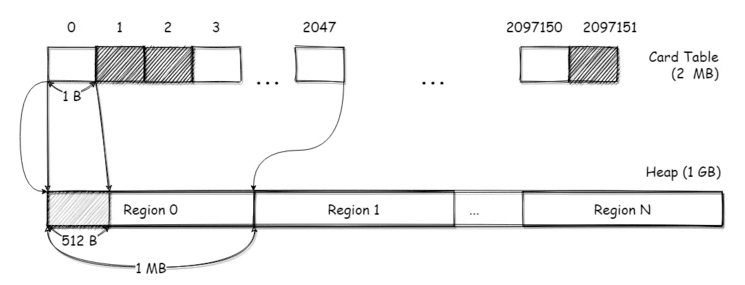
那么查找一个对象所在的 Card Page 只需要简单的计算就可以得出:( 对象地址 - 堆开始地址 ) / 512 Page 标记为 0,表示对应的区域中没有对新生代的引用;Page 标记为 1(Dirty),表示有对新生代的引用。使用 Cart Table 可以大大加快新生代的回收速度
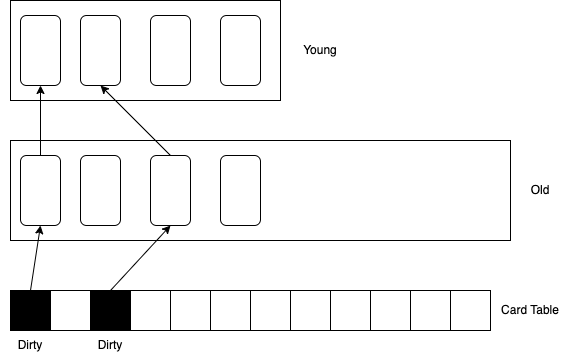
Q: 为什么卡表中一页大小为一字节,一个 bit 不就行了吗?
A: 之所以使用byte数组而不是bit数组主要是速度上的考量,现代计算机硬件都是最小按字节寻址的, 没有直接存储一个bit的指令
Q:为什么要从 Cart Table 中 Dirty Page 指向的老年代对象出现,而不是从 GC Roots 出发,怎么知道 Dirty Page 指向的老年代对象不是垃圾呢?不会发生循环引用吗?
A:不知道
Remember Set
G1 的每个 Region 中都有一个 Remember Set(RSet),通过 hash 实现,这个 hash 表的 key 是引用本区域的其他区域的地址,value 是一个数组,数组的元素是引用方的对象所对应的 Card Page 在 Card Table 中的下标
如下图所示,区域 B 中的对象 b 引用了区域 A 中的对象 a,这个引用关系跨了两个区域。b 对象所在的 Card Page 为 122,在区域 A 的 RSet 中,以区域 B 的地址作为 key,b 对象所在 Card Page 下标为 value 记录了这个引用关系,这样就完成了这个跨区域引用的记录
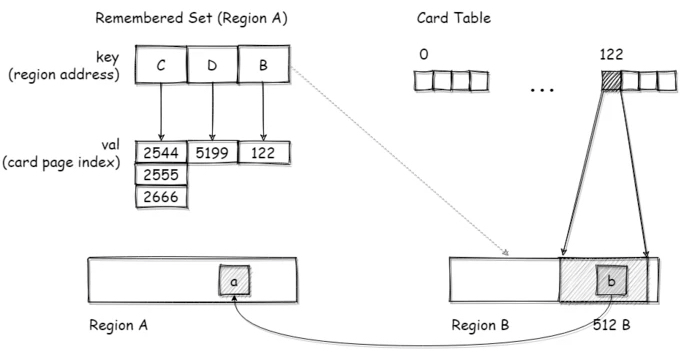
Q:为什么RSet 的 value 不直接保存对象地址,而是保存 Card Page,再通过 Card Page 对映射到一个地址区间?
A:不知道
比如 Region M 中有一个对象 N,如果 RSet 没有记录其他 Region 对 N 的索引,M 内部也没有对 N 的引用,那么 N 就是垃圾
这样 G1 就不需要全量扫描了,只需要查 RSet 和本 Region 就可以了
问题2. 为什么 G1 选择 SATB 而不是 Incremental Update?
Incremental Update 是将黑色标记为灰色,这样在重新标记灰色对象时,需要遍历它的全部属性,而我们关心的其实只是其中变化的引用关系,这样就产生了很多无用的工作;
SATB 因为可以借助 RSet 和 Card Table,对引用发生变化的白色对象,在 RSet 中查表即可了,所以效率更高
问题3. 怎么感知对象之间引用的变化
利用了写屏障,所谓写屏障,就是指给某个对象的成员变量赋值操作前后,加入一些处理(类似 Spring AOP 的概念)