Disruptor 是 LMAX 公司开发的一个高性能队列,开发初衷是解决 Java 提供的内存队列的延迟问题。目前有很多知名项目都应用了 Disruptor 以获得高性能,包括 Apache Storm、Camel、Log4j2 等,大量项目借鉴了它的设计机制,故了解 Disruptor 的实现原理是有必要的
这里所说的队列,是系统内部的内存队列,不是分布式队列
本文代码基于 disruptor:4.0.0 源码地址:https://github.com/LMAX-Exchange/disruptor
Java 内存队列存在的延迟问题
并发场景下,多个线程操作一个队列,需要考虑线程安全问题。jdk 提供的线程安全队列,Java的内置队列如下表所示
| 内置队列 | 有界性 | 数据结构 | 线程安全方案 |
|---|---|---|---|
| ArrayBlockingQueue | 有界 | 加锁 | arraylist |
| LinkedBlockingQueue | 可选 | 加锁 | linkedlist |
| ConcurrentLinkedQueue | 无界 | 无锁 | linkedlist |
| LinkedTransferQueue | 无界 | 无锁 | linkedlist |
| PriorityBlockingQueue | 无界 | 加锁 | heap |
| DelayQueue | 无界 | 加锁 | heap |
java 线程安全的内置队列,由于锁争抢、伪共享存在一定的性能问题,原因如下
GC 与访问速度
由于链表结构相比于数组,更容易出现内存碎片,更容易触发垃圾回收,而且一般队列在使用中,都是 FIFO 生产消费场景,很少会遇到中间插入/删除的情况,所以数组比链表有更高的内存利用率和更少的 GC 次数
另外,连续的内存空间可以通过索引定位,比链表有更快的访问速度
加锁与CAS的性能比较
加锁采用悲观锁的思想,认为线程会冲突,对数据操作之前,先加锁再执行,执行之后解锁,同时只有一个线程持有锁和访问数据
CAS 采用乐观锁的思想,认为线程不会冲突,先执行,记录数据最初的值,执行完给数据赋值时,比较数据当前值与最初值是否一致,如果一致,则这期间没有其他线程操作,或无效操作,可以赋值;如果不一致,则放弃赋值,重新执行,直到赋值成功。CAS 是 CPU 的一个指令,由 CPU 保证原子性
可以发现,如果执行动作很轻量,CAS 的成本更低,如果执行动作很耗时,应该选择加锁
ArrayBlockingQueue 通过加锁控制并发,竞争锁会导致线程挂起、等待、恢复,这个过程存在很大开销,对性能有严重的影响
这里直接参考 Disruptor 论文中的实验数据:
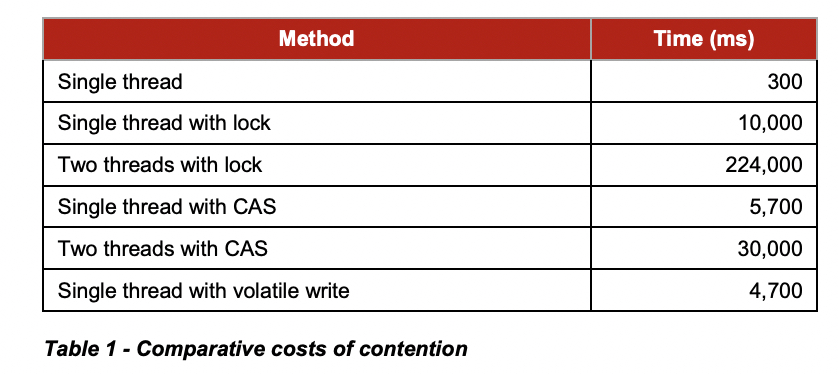
从上图可知:
单线程:不加锁的性能 > CAS操作的性能 > 加锁的性能
多线程:CAS操作的性能 > 加锁的性能
所以加锁的性能是最差的
伪共享
多级缓存
为了解决 cpu 处理速度与内存访问速度的差异,cpu 设置了 L1、L2、L3 三级缓存,越靠近 cpu 的缓存,速度越快,容量越小。当 CPU 读取数据时,会先到 L1 查找,如果没有再去 L2、L3,最后是内存,走的越远耗时越长
CPU 访问不同级别缓存/内存的耗时如下
| 位置 | 耗时 |
|---|---|
| 内存 | 60-80 ns |
| L3 cache | 15 ns |
| L2 cache | 3 ns |
| L1 cache | 1 ns |
可见 CPU 从内存读数据比 L1 慢了 2 个数量级
缓存写入与失效
缓存由多个缓存行(cache line)组成,每个 cache line 为 64 字节,可以存 8 个 long 类型变量
CPU 在缓存中没有找到数据,到内存中读到数据后,会写入缓存中。CPU 每次从内存拉数据,会把相邻的 64 字节(将内存空间按 64 字节分成小块)一起写入缓存的一个 cache line 中
比如在访问一个 long 数组 arr 时,假设 arr[0] ~ arr[7] 在一个 64 字节内存块中,读取了 arr[0],会把 arr[1] ~ arr[7] 也加载到缓存,这样再访问 arr[1] 时,直接在 L1 中读,不需要到内存中,提高了读取速度
当 cache line 对应的内存数据被修改,由于缓存和内存数据不一致,则 cache line 失效,需要重新到内存读,在多 CPU 下,需要让所有 CPU 的缓存中的 cache line 都失效
伪共享的验证
这样会出现这样一个场景:CPU1 不断读 arr[0],CPU2 不断写 arr[1],CPU1 本可以从自己的 L1 cache 中拿到 arr[0] 的值,却由于 CPU2 的写操作,导致自己的 L1 cache 中对应的 cache line 不停失效,不得不到内存中读数据。看似两个 CPU 在处理不同的变量,却互相影响了,这种无法充分利用 cache line 的现象,称为伪共享
对于伪共享,一般的解决方案,是增大变量之间的间隔,使两个变量不可能出现在一个 cache line 上,以空间换时间
实验验证
1 | public class Share { |
上面的例子,runInFlaseShare(伪共享)方法让每个线程访问的数据存在位于同一个缓存行中的情况,runInShare(共享)方法通过设置了 8 * 8 = 64 byte,让每个线程访问的数据一定不在同一个缓存行中
分别执行 runInFlaseShare 和 runInShar 的测试方法,运行 10 次取均值结果如下:
| 方法 | 耗时 |
|---|---|
| runInFlaseShare | 5737 ms |
| runInShare | 765 ms |
可以看到伪共享耗时是共享耗时的 7.5 倍
问题讨论
可以看到三个问题:GC次数、线程安全方案 和 伪共享,会让 java 内置线程安全队列,产生一定性能问题,如果让我们解决这些问题,应该如何设计队列呢
思路:
- 使用数组结构
- 使用 CAS 控制并发
- 让队列的元素不在同一个缓存行中,避免伪共享发生
按照这个思路,把 ArrayBlockingQueue 的并发控制从加锁改为 CAS,再对其中所有元素前后都插入 4 个 8 字节,是不是就实现了一个高效的内存队列呢,下面看下 Disruptor 的做法
Disruptor 的设计方案
在了解 Disruptor 如何解决上面问题之前,先要了解一些术语
术语介绍
先看一个简单的栗子
1 | // 创建Disruptor |
下面解释栗子中出现的术语
- Event:存放消息的单位
- Ring Buffer:环形数据缓冲区,一个首尾相接的环,用于存放 Event ,供生产者存入数据,和消费者拉取数据
- Sequence:序列,用于记录消息位置
- Sequencer:生产者,有单生产者和多生产者两种实现
- Sequence Barrier:序列屏障,控制消费者消费进度,防止消费到不可用消息
- Wait Strategy:等待策略,消费者等待生产者的策略
- Event Processor:消息处理器,循环从 RingBuffer 批量获取 Event 并执行 Event Handler
- Event Handler:执行消费逻辑
Event
存放消息,如:
1 |
|
Event Factory
创建消息的工厂
1 | class EventFactory implements com.lmax.disruptor.EventFactory<Event> { |
Sequence
一个数组 arr,我们通过 arr[i] 可以取到一个位置的元素,但是这样是线程不安全的,比如线程 A 想取第 i 个元素,在读数据前,其他线程修改了 i 的值,这样线程 A 取到了错误的值;Sequence 用来代替 i ,线程安全的从数组中取数
用来记录 Ring Buffer 中槽的位置,结构如下

前面提到,一个缓存行是 64 字节,Sequence 通过在 value 前后填充 56 字节,使得 value 一定独享一个缓存行,避免了伪共享
更新 Sequence 的 value:
1 | public long addAndGet(long increment) { |
通过 CAS 的方式,更新 value 的值,即当 currentValue 等于内存中 value 的值,才为 value 赋值
Sequence 通过填充字节和CAS,优化了并发场景下读写 Sequence 的性能
令 sequence B 是可消费的最后一个槽的索引,那么消费者线程 N 再每次消费时,都要读 B 的值,判断当前索引是否小于 B,假设 B 没有填充字节,则有可能 B 所在 cache line 的其他数据被写,导致缓存失效,N 需要从内存中读 B 的值;有了填充字节,只要 B 没有被写,缓存就不会失效
Sequence 的功能与 AtomicLong 的功能几乎一致,在 AtomicLong 的基础上优化了缓存行伪共享的问题
Sequencer
生产者,有两种实现:单生产者(SingleProducerSequencer)和多生产者(MultiProducerSequencer)
SingleProducerSequencer
一个 Ring Buffer 只有一个生产者
SingleProduerSequencer 的结构如下 
nextValue:下一个可申请的序列
cachedValue:缓存最小已被占用的序列,用来计算剩余序列是否足够被申请
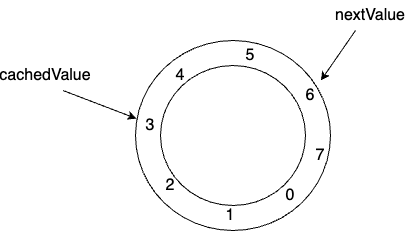
如图,nextValue = 6,cachedValue = 3,说明序列 3、4、5 已被占用,6、7、0、1、2 可申请
下面看几个重要方法:
| 方法 | 功能 |
|---|---|
| SingleProducerSequencer(final int bufferSize, final WaitStrategy waitStrategy) | 构造方法bufferSize:ring buffer 的大小,必须是 2 的 n 次幂waitStrategy:生产消息时发现队列已满的等待策略 |
| boolean hasAvailableCapacity(int requiredCapacity) | 是否有可用容量,通过 nextValue + requiredCapacity 与 cachedValue 比较,判断剩余的序列是否够用 |
| long next(int n) | 声明后面 n 个序列的状态是发布中 |
| void publish(long sequence) | 发布一个序列,意味着这个序列已经被充填了数据(已生产) |
SingleProducerSequencer 生产 n 个消息的执行流程是:
- 创建一个大小为 bufferSize 的 ring buffer(构造方法)
- 查看当前容量是否足够(hasAvailableCapacity 方法)
- 如果容量足够,声明 n 个序列为发布中(next 方法)
- 为这 n 个序列填充数据,将已填充数据的序列的状态改为已发布(publish 方法)
- 如果容量不足,执行等待策略
MultiProducerSequencer
一个 Ring Buffer 有多个生产者
MultiProducerSequencer 的结构如下
1 | private final Sequence gatingSequenceCache = new Sequence(Sequencer.INITIAL_CURSOR_VALUE); |
gatingSequenceCache:记录生产的位置
availableBuffer:记录每个槽当前数据所在的圈数,初始值 -1,用来判断数据是否可用(可以被消费),大小为 buffer size
indexMask = bufferSize - 1,用来计算 sequence 在 availableBuffer 中的位置:index = sequence & indexMask = sequence & (2^n - 1)
indexShift = log2(bufferSize),用来计算 availableBuffer[i] 的值,flag = availableBuffer[i] = sequence >>> indexShift
下面介绍几个重要方法
1 | // 计算 sequence 的槽位号 |
比如 ring buffer 的 buffer size = 8,indexMask = 7(0111),indexShift = log2(8) = 3
sequence(13) 的槽位号 index = 1101 & 0111 = 0101 = 5,圈数 flag = 13 >>> 3 = 1
1 | public long tryNext(final int n) throws InsufficientCapacityException |
tryNext 方法将 cursor + n,cursor 是 ring buffer 上可用的最高位 sequence,比如一个线程 A 想向队列写 n 个消息,通过 tryNext(n) 即可将 cursor 向前移动 n 位,则 [cursor + 1, curosr + n] 区间内的槽只能由线程 A 写入,其他线程再写入,需要从 cursor + n + 1 开始写,从而避免了每次写都要处理并发冲突;这么看来,在写入 ring buffer 时,先在线程内部积累一些数据,再批量写入
不过这样带来一个问题:ring buffer 被分成多份同时写,不能通过比较消费最高位和生产最高位的大小,来判断槽位是否可用了,因为中间可能存在没生产完的槽位,availableBuffer 就是用来解决这个问题的
生产者在 sequence 的槽位 i 上生产完消息,执行 publish,将 availableBuffer[i] 的值设为 flag
1 | public void publish(long sequence) { |
例如 buffer size = 8,生产者写完 sequence(13),availableBuffer[5] = 1
消费者来读 sequence(5),flag = 0 不等于 availableBuffer[5],说明 sequence(5) 不可用,已经被 sequence(13) 覆盖掉了
sequence(14) 的 index = 6,flag = 1,availableBuffer[6] = 0,不相等,说明 sequence(14) 不可用,因为 sequence(14) 还是第一圈的旧数据,已经被消费过了,第二圈的还没有写入
MultiProducerSequencer 生产 n 个消息的执行流程是:
- 创建一个大小为 bufferSize 的 ring buffer、availableBuffer,indexMask,indexShift
- tryNext 申请 n 个连续槽位(CAS)
- 如果剩余槽位足够,将 cursor 后移 n 位
- 向槽位写入数据,通过 publish 修改 availableBuffer 对应位置的状态(flag)
- 如果槽位不足,执行等待策略
Ring Buffer
Ring Buffer 是一个环形数据缓冲区,用于存放 Event,数据结构如下

说明:
- 前后的 56 byte 用于填充缓存行,防止 indexMask 和 Sequencer 发生伪共享
- indexMask 用于计算 sequence 的槽位号,同 Sequencer
- entries 是 Event 对象引用的数组,长度为 2 的 n 次幂,每个元素大小为 4 byte(开启指针压缩),前后 32 个元素被指定为 BUFFER_PAD(128 byte)
- BufferSize:Sequencer 的长度
不是很理解 BUFFER_PAD 的长度为什么设计为 32,缓存行填充只需要 56 byte,14 个元素即可
指针压缩:64位系统中,每个指针默认大小 8 byte,为了节省内存空间,开启指针压缩可以让指针大小缩小为 4 byte(默认开启);32 位系统指针都是 4 byte,不存在指针压缩
重要方法:
1 | // 向后申请一个 sequence |
可以看到,ring buffer 都是通过 sequencer 来操作槽位的状态
Sequence Barrier
屏障是用来控制消费者,消费者只能消费屏障内的消息,防止消费到不可用的消息
消费者消费的模式分为两种:
- 依赖生产者最大可达数据
- 消费者依赖图
为了更简单明白原理,只对模式1分析
Sequence Barrier 的结构如下
sequencer:生产者
waitStrategy:等待策略
cursorSequence:当前生产到的消息
dependentSequences:依赖的消息
消费者希望消费 sequence 位置上的消息前,要通过屏障的 waitFor 方法来获取可用的位置(屏障边界),消费者拿到可用位置后,就可以消费这个位置以内的消息
比如:连续可用消息的最大位置是 100,消费者 A 希望消费位置 90,则屏障返回 100,说明此刻消费者 A 可以消费位置 100 以内的消息;消费者 B 希望消费位置 101,由于 101 还未被生产,屏障会执行等待策略,阻止 B 消费
代码解读:
1 | // 入参:sequence 希望消费的位置 |
当消费者线程进入休眠,生产者生产了一条消息,就要通知所有消费者起来干活,是通过屏障的 alert 方法
1 | public void alert() |
上面两个方法都用到了 WaitStrategy 的方法,下面继续介绍
WaitStrategy
消费者消费时,可能遇到当前 sequence 是不可用状态,需要按照给定的策略等待
有以下几个等待策略
| 策略 | 适用场景 |
|---|---|
| BlockingWaitStrategy | CPU 资源宝贵,吞吐量和低延迟次要 |
| BusySpinWaitStrategy | CPU 性能比较好,追求高吞吐量和低延迟 |
| TimeoutBlockingWaitStrategy | CPU 资源宝贵,吞吐量和低延迟次要 |
| LiteTimeoutBlockingWaitStrategy | CPU 资源宝贵,吞吐量和低延迟次要 |
| PhasedBackoffWaitStrategy | CPU 资源宝贵,吞吐量和低延迟次要 |
下面分别介绍
BlockingWaitStrategy
因为消息之间可能存在依赖,需要等待 dependentSequence 被消费,为了简化理解,我们先认为消息之间没有依赖,即 dependentSequence = cursorSequence(当前消息)
该策略使用系统调用让消费线程等待,在生产一条消息后再唤醒消费线程,当吞吐量和低延迟不如 CPU 资源重要时,可以使用此策略
1 |
|
在上面代码中,消费者期望位置不可用,会先占有 mutex 锁,通过 mutex.wait() 方法让线程进入等待状态
当生产者调用 barrier 的 alert 方法,会调用 waitStrategy 的 signalAllWhenBlocking 来唤醒 mutex 上等待的消费者
1 |
|
BusySpinWaitStrategy
与 BlockWaitStrategy 的区别是,不需要线上等待,而是周期性轮询直到位置可用
这个策略避免了系统调用,不过增大了 CPU 的 busy 程度,如果 CPU 性能比较好可以考虑
1 | public long waitFor( |
TimeoutBlockingWaitStrategy
在 BlockWaitStrategy 基础上加入了线程等待的最大时间,防止线程无限期的等待下去
1 | if (cursorSequence.get() < sequence) |
LiteTimeoutBlockingWaitStrategy
在 TimeoutBlockingWaitStrategy 基础上,加上了是否需要通知校验的优化,只有在有消费者等待的情况下才会 notifyAll
1 | public void signalAllWhenBlocking() |
PhasedBackoffWaitStrategy
先自旋,自旋次数达到阈值后,采用 backup 策略
更多的策略可阅读源码
Event Processor
消费处理器,用于执行消费逻辑
实现:BatchEventProcessor
结构:
- dataProvider:用于读取某个位置上的数据
- sequenceBarrier:屏障
- eventHandler:消息处理器
- maxBatchSize:消费一批消息的最大数量
- batchRewindStrategy:重试策略
- sequence:当前已消费的位置
执行消费方法:
1 | private void processEvents() |
流程汇总
通过下面几个步骤串起 disruptor 生产和消费过程(多生产者,基于最大生产消息)
步骤1. 生产者 P1、P2、P3 调用 MultiProducerSequencer.tryNext(n) 使用 CAS 修改 cursor 的值,分别申请 11、15、25 个位置,并将 ring buffer 的 cursor 后移至 50,同时生产消息;生产完位置 sequence,令 availableBuffersequence = 0
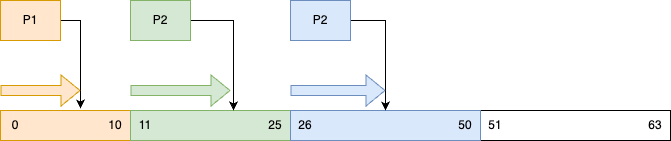
假设P1生产完 sequence = 7 后阻塞
步骤2. 消费者 C1 开始消费
C1 调用 barrier.waitFor(1),maxBatchSize = 10,获取可消费的最大位置 = 7,C1 开始从 0 开始消费到 7。消费完,C1 的 sequence = 7
步骤3. C1 调用 barrier.waitFor(8),发现位置 8 的消息不可用(availableByffer[8] = -1 不等于 0),执行等待策略
步骤4. P1 此时阻塞结束,生产完消息 8 的消息,执行 publish,将 availableBuffer[8] = 0,通过 barrier.alert 方法通知 C1
步骤5. C1 被唤醒,barrier.waitFor(8) = 8,消费位置 8 的消息
总结
Disruptor 是通过下面设计思想,解决内存队列并发性能问题的
- 环形数组:环形数组可以覆盖过期的数据,减少 GC 次数;同时,数组可以充分利用 CPU 的缓存共享机制
- 预申请:提前申请一段独享空间,避免每次写都争抢资源
- 无锁:通过 CAS 保证线程安全
- 属性填充:避免伪共享